- f
World Clusters map
- data.apps.fao.org
Updated Mar 2, 2024 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCite(2024). World Clusters map [Dataset]. https://data.apps.fao.org/map/catalog/srv/resources/datasets/d772cf60-88fd-11da-a88f-000d939bc5d8Dataset updatedMar 2, 2024Area coveredWorldDescription
EmailClick to copy linkLink copiedCite(2024). World Clusters map [Dataset]. https://data.apps.fao.org/map/catalog/srv/resources/datasets/d772cf60-88fd-11da-a88f-000d939bc5d8Dataset updatedMar 2, 2024Area coveredWorldDescriptionWorld cluster map of the world based on a Coastal zone (LOICZ) database received in 1995 from the Netherlands Institute for Sea Research (NIOZ).
Canadian Cluster Map Portal Data
- open.canada.ca
csvUpdated Feb 21, 2022+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteInnovation, Science and Economic Development Canada (2022). Canadian Cluster Map Portal Data [Dataset]. https://open.canada.ca/data/en/dataset/83c19800-74a9-4da5-8d67-d2e0611e167fcsvAvailable download formatsDataset updatedFeb 21, 2022LicenseOpen Government Licence - Canada 2.0https://open.canada.ca/en/open-government-licence-canada
License information was derived automaticallyTime period coveredJan 1, 2006 - Dec 31, 2017Area coveredCanadaDescriptionThe datasets provided encompass all the statistics found on the Canadian Cluster Map Portal. Moreover, additional information such as cluster-concordance and cluster descriptions are provided to allow for accurate analysis of the data.
- N
Connectivity-Based Parcellation of the Human Orbitofrontal Cortex: K=5...
- neurovault.org
niftiUpdated Nov 18, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2024). Connectivity-Based Parcellation of the Human Orbitofrontal Cortex: K=5 cluster map [Dataset]. http://identifiers.org/neurovault.image:887626niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:887626Dataset updatedNov 18, 2024LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionK=5 cluster map based on N=13 participants.
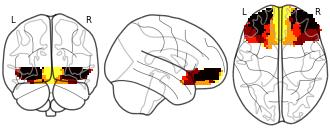
Collection description
K-means cluster maps of orbitofrontal cortex with K=2, 3, 4, 5, 6, and 7 clusters based on resting-state fMRI data.
Subject species
homo sapiens
Modality
fMRI-BOLD
Analysis level
group
Cognitive paradigm (task)
rest eyes open
Map type
R
- M
School Clusters Map
- data.montgomeryschoolsmd.org
csv, xlsx, xmlUpdated Jun 23, 2016 Hydrochemical Clusters Map: K-Means Clustering Results for Southcentral...
- figshare.com
htmlUpdated Jan 11, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAbhinav Choudhary (2025). Hydrochemical Clusters Map: K-Means Clustering Results for Southcentral Alaska [Dataset]. http://doi.org/10.6084/m9.figshare.28188833.v1htmlAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.28188833.v1Dataset updatedJan 11, 2025AuthorsAbhinav ChoudharyLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyArea coveredSouthcentral Alaska, AlaskaDescriptionThis interactive map shows the spatial distribution of hydrochemical data across Southcentral Alaska using K-Means clustering. The dataset includes key hydrochemical measurements, and each cluster is represented by a unique color on the map. The map is generated using Leaflet and Folium libraries in Python.The static version is available in the main manuscript, while this HTML file provides a dynamic exploration of clustering results.Contact: Abhinav Choudhary (Chandigarh University, MSc Data Science)Date of creation: 2025-01-11
- M
Map of Service Areas - Clusters
- data.montgomeryschoolsmd.org
csv, xlsx, xmlUpdated Jun 23, 2016ShareFacebookTwitterEmailClick to copy linkLink copiedCite(2016). Map of Service Areas - Clusters [Dataset]. https://data.montgomeryschoolsmd.org/w/3hy6-nzu3/tf2z-49td?cur=u8XX-kpqrOU&from=igR9PPcIPGkcsv, xlsx, xmlAvailable download formatsDataset updatedJun 23, 2016DescriptionMCPS Cluster Service Areas
- d
Neighborhood Clusters
- catalog.data.gov
- opendata.dc.gov
Updated Feb 5, 2025+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteD.C. Office of the Chief Technology Officer (2025). Neighborhood Clusters [Dataset]. https://catalog.data.gov/dataset/neighborhood-clustersDataset updatedFeb 5, 2025Dataset provided byD.C. Office of the Chief Technology OfficerDescriptionThis data set describes Neighborhood Clusters that have been used for community planning and related purposes in the District of Columbia for many years. It does not represent boundaries of District of Columbia neighborhoods. Cluster boundaries were established in the early 2000s based on the professional judgment of the staff of the Office of Planning as reasonably descriptive units of the City for planning purposes. Once created, these boundaries have been maintained unchanged to facilitate comparisons over time, and have been used by many city agencies and outside analysts for this purpose. (The exception is that 7 “additional” areas were added to fill the gaps in the original dataset, which omitted areas without significant neighborhood character such as Rock Creek Park, the National Mall, and the Naval Observatory.) The District of Columbia does not have official neighborhood boundaries. The Office of Planning provides a separate data layer containing Neighborhood Labels that it uses to place neighborhood names on its maps. No formal set of standards describes which neighborhoods are included in that dataset.Whereas neighborhood boundaries can be subjective and fluid over time, these Neighborhood Clusters represent a stable set of boundaries that can be used to describe conditions within the District of Columbia over time.
- e
Structural vision RO, Regional clusters — Vision map
- data.europa.eu
Updated Jul 26, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2023). Structural vision RO, Regional clusters — Vision map [Dataset]. https://data.europa.eu/data/datasets/8c528f4a-7814-4a47-8ed3-8bf8fa46b6c3Dataset updatedJul 26, 2023DescriptionEconomic knowledge clusters. A distinction is made between ‘Metropolitan region’, ‘Economic knowledge cluster’ and ‘Indication economic cluster outside Brabant’.
- a
School Cluster Boundaries (MCPS)
- hub.arcgis.com
- data-mcplanning.hub.arcgis.com
- +1more
Updated Jul 20, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMontgomery Maps (2021). School Cluster Boundaries (MCPS) [Dataset]. https://hub.arcgis.com/maps/MCPlanning::school-cluster-boundaries-mcpsDataset updatedJul 20, 2021Dataset authored and provided byMontgomery MapsLicenseMIT Licensehttps://opensource.org/licenses/MIT
License information was derived automaticallyArea coveredMontgomery County Public Schools,DescriptionGroups of geographically defined attendance areas. They include elementary and middle-level schools that feed into particular high schools and consortium schools.For further details: https://www2.montgomeryschoolsmd.org/departments/Clusteradmin/Clusters/indexFor more information, contact: GIS Manager Information Technology & Innovation (ITI) Montgomery County Planning Department, MNCPPC T: 301-650-5620
- Z
Clusters of interactions common between the Parkinson's disease map and the...
- data.niaid.nih.gov
Updated Dec 18, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMarek Ostaszewski (2022). Clusters of interactions common between the Parkinson's disease map and the Ageing map [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_7448588Dataset updatedDec 18, 2022Dataset authored and provided byMarek OstaszewskiLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis set of files was generated using the script demonstrating the use of MINERVA Net repository.
The script is available under:
https://gitlab.lcsb.uni.lu/minerva/api-scripts/-/blob/master/R/API-minervanet.R
The diagrams should be opened with the CellDesigner software (https://www.celldesigner.org/).
- c
Cluster Maps
- data.catchmentbasedapproach.org
Updated Jun 4, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDefra Group Open (2024). Cluster Maps [Dataset]. https://data.catchmentbasedapproach.org/maps/defra-open::cluster-maps-1Dataset updatedJun 4, 2024Dataset authored and provided byDefra Group OpenLicenseMIT Licensehttps://opensource.org/licenses/MIT
License information was derived automaticallyArea coveredDescriptionCluster Maps
- e
Milky Way nuclear star cluster extinction map - Dataset - B2FIND
- b2find.eudat.eu
Updated Oct 28, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCite(2023). Milky Way nuclear star cluster extinction map - Dataset - B2FIND [Dataset]. https://b2find.eudat.eu/dataset/f8ba9e0a-80cb-5574-b6ba-ceec5c0561b5Dataset updatedOct 28, 2023DescriptionAlthough the Milky Way Nuclear Star Cluster (MWNSC) was discovered more than four decades ago, several of its key properties have not been determined unambiguously up to now because of the strong and spatially highly variable interstellar extinction toward the Galactic centre. In this paper we aim at determining the shape, size, and luminosity/mass of the MWNSC.In order to investigate the properties of the MWNSC, we use Spitzer/IRAC images at 3.6 and 4.5{mu}m, where interstellar extinction is at a minimum but the overall emission is still dominated by stars. We correct the 4.5{mu}m image for PAH emission with the help of the IRAC 8.0{mu}m map and for extinction with the help of a [3.6-4.5] colour map. Finally, we investigate the symmetry of the nuclear cluster and fit it with Sersic, Moffat, and King models. We present an extinction map for the central ~300x200pc^2^ of the Milky Way, as well as a PAH-emission and extinction corrected image of the stellar emission, with a resolution of about 0.20pc. We find that the MWNSC appears in projection intrinsically point-symmetric, that it is significantly flattened, with its major axis aligned along the Galactic Plane, and that it is centred on the black hole, Sagittarius A. Its density follows the well known approximate {rho}{prop.to}r^-2^-law at distances of a few parsecs from Sagittarius A, but becomes as steep as about {rho}{prop.to}r^-3^ at projected radii around 5pc. We derive a half light radius of 4.2+/-0.4pc, a total luminosity of L_MWNSC,4.5{mu}m_=4.1+/-0.4x10^7^L_{sun}, and a mass of M_MWNSC=2.1+/-0.4x10^7^M_{sun}_. The overall properties of the MWNSC agree well with the ones of its extragalactic counterparts, which underlines its role as a template for these objects. Its flattening agrees well with its previously established rotation parallel to Galactic rotation and suggests that it has formed by accretion of material that fell in preferentially along the Galactic Plane. Our findings support the in situ growth scenario for nuclear clusters and emphasize the need to increase the complexity of theoretical models for their formation and for the interaction between their stars and the central black hole in order to include rotation, axisymmetry, and growth in recurrent episodes. Cone search capability for table J/A+A/566/A47/list (List of FITS maps) Associated data
Indicative Flood Risk Areas - Clusters - Dataset - data.gov.uk
- ckan.publishing.service.gov.uk
Updated Nov 27, 2018+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteckan.publishing.service.gov.uk (2018). Indicative Flood Risk Areas - Clusters - Dataset - data.gov.uk [Dataset]. https://ckan.publishing.service.gov.uk/dataset/indicative-flood-risk-areas-clustersDataset updatedNov 27, 2018DescriptionPLEASE NOTE: this dataset has been retired. It has been superseded by data for Flood Risk Areas: https://environment.data.gov.uk/dataset/f3d63ec5-a21a-49fb-803a-0fa0fb7238b6 The Indicative Flood Risk Areas are primarily based on an aggregated 1km square grid Updated Flood Map for Surface Water (1 in 100 and 1000 annual probability rainfall), informally referred to as the “blue square map”. • Cluster Maps – are aggregations of 3km by 3km squares that each contain at least 4 (in Wales) or 5 (in England) touching "blue squares" (i.e. 1km grid squares where one of the thresholds above is exceeded) This dataset forms part of Indicative Flood Risk Areas (shapefiles) A bundle download of all Indicative Flood Risk Areas spatial datasets is also available from this record. Please see individual records for full details and metadata on each product. Attribution statement: © Environment Agency copyright and/or database right 2016. All rights reserved.
- U
Database for the Geologic Map of Three Sisters Volcanic Cluster, Cascade...
- data.usgs.gov
- s.cnmilf.com
- +2more
Updated Feb 24, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteJeff Peters; Joel Robinson; Edward Hildreth; Judith Fierstein; Andrew Calvert (2024). Database for the Geologic Map of Three Sisters Volcanic Cluster, Cascade Range, Oregon [Dataset]. http://doi.org/10.5066/P9IYBCRIUnique identifierhttps://doi.org/10.5066/P9IYBCRIDataset updatedFeb 24, 2024AuthorsJeff Peters; Joel Robinson; Edward Hildreth; Judith Fierstein; Andrew CalvertLicenseU.S. Government Workshttps://www.usa.gov/government-works
License information was derived automaticallyTime period covered2020Area coveredThree Sisters, Cascade Range, OregonDescriptionA database of geologic map of Three Sisters Volcanic Cluster as described in the original abstract: The geologic map represents part of a late Quaternary volcanic field within which scores of eruptions have taken place over the last 50,000 years, some as recently as ~1,500 years ago. No rocks of early Pleistocene (or greater) age crop out within the map area, although volcanic and derivative sedimentary rocks of Miocene and Pliocene age are widespread to the east and west and are certainly buried beneath the younger volcanic field. Of the 145 volcanic map units described herein, only 22 are certainly older than late Pleistocene (>126 ka), and 12 are postglacial (<15 ka). The oldest unit identified yields an age of 532+/-7 ka, and the second oldest, 374+/-6 ka. Compositionally, 10 percent of the units are true basalt; 36 percent, basaltic andesite; 20 percent, andesite; 21.5 percent, dacite; and only 12.5 percent, rhyodacite or rhyolite. Most of the 145 volcanic map unit ...
- p
Busia K-Means Cluster Map
- purr.purdue.edu
Updated Nov 18, 2019ShareFacebookTwitterEmailClick to copy linkLink copiedCiteJoshua Minai; Darrell Schulze (2019). Busia K-Means Cluster Map [Dataset]. http://doi.org/10.4231/4Q9T-FT90Unique identifierhttps://doi.org/10.4231/4Q9T-FT90Dataset updatedNov 18, 2019Dataset provided byPURRAuthorsJoshua Minai; Darrell SchulzeLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyArea coveredBusiaDescriptionMap that mimics the geometry of 'fully developed slopes'.
- f
R script and datasets - Cluster Analysis and Heat maps
- figshare.com
txtUpdated May 30, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteChui Pin Leaw; Po Teen Lim; Li Keat Lee (2020). R script and datasets - Cluster Analysis and Heat maps [Dataset]. http://doi.org/10.6084/m9.figshare.12387242.v2txtAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.12387242.v2Dataset updatedMay 30, 2020Dataset provided byfigshareAuthorsChui Pin Leaw; Po Teen Lim; Li Keat LeeLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis folder contained R scripts and data sets used to generate clustering dendogram and heatmaps as shown Fig. 3.
Spatial and space-time clusters of SARS-CoV-2 infection in household cats in...
- figshare.com
xlsUpdated May 2, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteChi Chen; Mathias Martins; Mohammed Nooruzzaman; Dipankar Yettapu; Diego G. Diel; Jennifer M. Reinhart; Ashlee Urbasic; Hannah Robinson; Csaba Varga; Ying Fang (2024). Spatial and space-time clusters of SARS-CoV-2 infection in household cats in Illinois, United States, 2021–2023. [Dataset]. http://doi.org/10.1371/journal.pone.0299388.t002xlsAvailable download formatsUnique identifierhttps://doi.org/10.1371/journal.pone.0299388.t002Dataset updatedMay 2, 2024AuthorsChi Chen; Mathias Martins; Mohammed Nooruzzaman; Dipankar Yettapu; Diego G. Diel; Jennifer M. Reinhart; Ashlee Urbasic; Hannah Robinson; Csaba Varga; Ying FangLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyArea coveredUnited States, IllinoisDescriptionSpatial and space-time clusters of SARS-CoV-2 infection in household cats in Illinois, United States, 2021–2023.
- a
Berwick Crashes SR 4
- maine.hub.arcgis.com
Updated Jan 31, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteState of Maine (2023). Berwick Crashes SR 4 [Dataset]. https://maine.hub.arcgis.com/maps/maine::berwick-crashes-sr-4Dataset updatedJan 31, 2023Dataset authored and provided byState of MaineArea coveredDescriptionThis crash dataset does include crashes from 2023 up until near the end of January that have been reviewed and loaded into the Maine DOT Asset Warehouse. This crash dataset is static and was put together as an example showing the clustering functionality in ArcGIS Online. In addition the dataset was designed with columns that include data items at the Unit and Persons levels of a crash. The feature layer visualization by default will show the crashes aggregated by the predominant crash type along the corridor. The aggregation settings can be toggled off if desired and crashes can be viewed by the type of crash. Both the aggregation and standard Feature Layer configurations do include popup settings that have been configured.As mentioned above, the Feature Layer itself has been configured to include a standard unique value renderer based on Crash Type and the layer also includes clustering aggregation configurations that could be toggled on or off if the user were to add this layer to a new ArcGIS Online Map. Clustering and aggregation options in ArcGIS Online provide functionality that is not yet available in the latest version of ArcGIS Pro (<=3.1). This additional configuration includes how to show the popup content for the cluster of crashes. Users interested in learning more about clustering and aggregation in ArcGIS Online and some more advanced options should see the following ESRI article (https://www.esri.com/arcgis-blog/products/arcgis-online/mapping/summarize-and-explore-point-clusters-with-arcade-in-popups/).Popups have been configured for both the clusters and the individual crashes. The individual crashes themselves do include multiple tables within a single text element. The bottom table does include data items that pertain to at a maximum of three units for a crash. If a crash includes just one unit then this bottom table will include only 2 columns. For each additional unit involved in a crash an additional column will appear listing out those data items that pertain to that unit up to a maximum of 3 units. There are crashes that do include more than 3 units and information for these additional units is not currently included in the dataset at the moment. The crash data items available in this Feature Layer representation includes many of the same data items from the Crash Layer (10 Years) that are available for use in Maine DOT's Public Map Viewer Application that can be accessed from the following link(https://www.maine.gov/mdot/mapviewer/?added=Crashes%20-%2010%20Years). However this crash data includes data items that are not yet available in other GIS Crash Departments used in visualizations by the department currently. These additional data items can be aggregated using other presentation types such as a Chart, but could also be filtered in the map. Users should refer to the unit count associated to each crash and be aware when a units information may not be visible in those situations where there are four or more units involved in a crash.
Clusters indicated as mapping priorities with their constituent diseases...
- plos.figshare.com
- datasetcatalog.nlm.nih.gov
xlsUpdated Jun 1, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDavid M. Pigott; Rosalind E. Howes; Antoinette Wiebe; Katherine E. Battle; Nick Golding; Peter W. Gething; Scott F. Dowell; Tamer H. Farag; Andres J. Garcia; Ann M. Kimball; L. Kendall Krause; Craig H. Smith; Simon J. Brooker; Hmwe H. Kyu; Theo Vos; Christopher J. L. Murray; Catherine L. Moyes; Simon I. Hay (2023). Clusters indicated as mapping priorities with their constituent diseases recommended for distribution modelling and current global mapping projects identified. [Dataset]. http://doi.org/10.1371/journal.pntd.0003756.t001xlsAvailable download formatsUnique identifierhttps://doi.org/10.1371/journal.pntd.0003756.t001Dataset updatedJun 1, 2023AuthorsDavid M. Pigott; Rosalind E. Howes; Antoinette Wiebe; Katherine E. Battle; Nick Golding; Peter W. Gething; Scott F. Dowell; Tamer H. Farag; Andres J. Garcia; Ann M. Kimball; L. Kendall Krause; Craig H. Smith; Simon J. Brooker; Hmwe H. Kyu; Theo Vos; Christopher J. L. Murray; Catherine L. Moyes; Simon I. HayLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescription- Indicates default null value.MAP—Malaria Atlas Project; WHO—World Health Organization; GBD—Global Burden of Disease; GAHI—Global Atlas of Helminth Infections; SEEG—Spatial Ecology and Epidemiology Group; APOC—African Programme for Onchocerciasis Control; GAT—Global Atlas of TrachomaClusters indicated as mapping priorities with their constituent diseases recommended for distribution modelling and current global mapping projects identified.
- a
Wards Socio Economic Clusters
- hub.arcgis.com
Updated Feb 15, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCitegISU (2023). Wards Socio Economic Clusters [Dataset]. https://hub.arcgis.com/maps/ISU::wards-socio-economic-clustersDataset updatedFeb 15, 2023Dataset authored and provided bygISUArea coveredDescriptionSee Publication: https://doi.org/10.1002/ecs2.4242 Policy interest in socio-ecological systems has driven attempts to define and map socio-ecological zones (SEZs), that is, spatial regions, distinguishable by their conjoined social and bio-geo-physical characteristics. The state of Idaho, USA, has a strong need for SEZ designations because of potential conflicts between rapidly increasing and impactful human populations, and proximal natural ecosystems. Our Idaho SEZs address analytical shortcomings in previously published SEZs by: (1) considering potential biases of clustering methods, (2) cross-validating SEZ classifications, (3) measuring the relative importance of bio-geo-physical and social system predictors, and (4) considering spatial autocorrelation. We obtained authoritative bio-geo-physical and social system datasets for Idaho, aggregated into 5-km grids = 25 km2, and decomposed these using principal components analyses (PCAs). PCA scores were classified using two clustering techniques commonly used in SEZ mapping: hierarchical clustering with Ward's linkage, and k-means analysis. Classification evaluators indicated that eight- and five-cluster solutions were optimal for the bio-geo-physical and social datasets for Ward's linkage, resulting in 31 SEZ composite types, and six- and five-cluster solutions were optimal for k-means analysis, resulting in 24 SEZ composite types. Ward's and k-means solutions were similar for bio-geo-physical and social classifications with similar numbers of clusters. Further, both classifiers identified the same dominant SEZ composites. For rarer SEZs, however, classification methods strongly affected SEZ classifications, potentially altering land management perspectives. Our SEZs identify several critical regions of social–ecological overlap. These include suburban interface types and a high desert transition zone. Based on multinomial generalized linear models, bio-geo-physical information explained more variation in SEZs than social system data, after controlling for spatial autocorrelation, under both Ward's and k-means approaches. Agreement (cross-validation) levels were high for multinomial models with bio-geo-physical and social predictors for both Ward's and k-means SEZs. A consideration of historical drivers, including indigenous social systems, and current trajectories of land and resource management in Idaho, indicates a strong need for rigorous SEZ designations to guide development and conservation in the region. Our analytical framework can be broadly applied in SES research and applied in other regions, when categorical responses—including cluster designations—have a spatial component.
FacebookTwitterWorld cluster map of the world based on a Coastal zone (LOICZ) database received in 1995 from the Netherlands Institute for Sea Research (NIOZ).