- f
Data Sheet 1_Multiplexing and massive parallel sequencing of targeted DNA...
- figshare.com
- frontiersin.figshare.com
docxUpdated Feb 28, 2025 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCiteBowen Zhu; Dean Li; Guojing Han; Xue Yao; Hongqin Gu; Tao Liu; Linghua Liu; Jie Dai; Isabella Zhaotong Liu; Yanlin Liang; Jian Zheng; Zheming Sun; He Lin; Nan Liu; Haidong Yu; Meifang Shi; Gaofang Shen; Zhaohui Hu; Lefeng Qu (2025). Data Sheet 1_Multiplexing and massive parallel sequencing of targeted DNA methylation to predict chronological age.docx [Dataset]. http://doi.org/10.3389/fragi.2025.1467639.s001docxAvailable download formatsUnique identifierhttps://doi.org/10.3389/fragi.2025.1467639.s001Dataset updatedFeb 28, 2025Dataset provided byFrontiersAuthorsBowen Zhu; Dean Li; Guojing Han; Xue Yao; Hongqin Gu; Tao Liu; Linghua Liu; Jie Dai; Isabella Zhaotong Liu; Yanlin Liang; Jian Zheng; Zheming Sun; He Lin; Nan Liu; Haidong Yu; Meifang Shi; Gaofang Shen; Zhaohui Hu; Lefeng QuLicense
EmailClick to copy linkLink copiedCiteBowen Zhu; Dean Li; Guojing Han; Xue Yao; Hongqin Gu; Tao Liu; Linghua Liu; Jie Dai; Isabella Zhaotong Liu; Yanlin Liang; Jian Zheng; Zheming Sun; He Lin; Nan Liu; Haidong Yu; Meifang Shi; Gaofang Shen; Zhaohui Hu; Lefeng Qu (2025). Data Sheet 1_Multiplexing and massive parallel sequencing of targeted DNA methylation to predict chronological age.docx [Dataset]. http://doi.org/10.3389/fragi.2025.1467639.s001docxAvailable download formatsUnique identifierhttps://doi.org/10.3389/fragi.2025.1467639.s001Dataset updatedFeb 28, 2025Dataset provided byFrontiersAuthorsBowen Zhu; Dean Li; Guojing Han; Xue Yao; Hongqin Gu; Tao Liu; Linghua Liu; Jie Dai; Isabella Zhaotong Liu; Yanlin Liang; Jian Zheng; Zheming Sun; He Lin; Nan Liu; Haidong Yu; Meifang Shi; Gaofang Shen; Zhaohui Hu; Lefeng QuLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionEstimation of chronological age is particularly informative in forensic contexts. Assessment of DNA methylation status allows for the prediction of age, though the accuracy may vary across models. In this study, we started with a carefully designed discovery cohort with more elderly subjects than other age categories, to diminish the effect of epigenetic drifting. We applied multiplexing and massive parallel sequencing of targeted DNA methylation, which let us to construct a model comprising 25 CpG sites with substantially improved accuracy (MAE = 2.279, R = 0.920). This model is further validated by an independent cohort (MAE = 2.204, 82.7% success (±5 years)). Remarkably, in a multi-center test using trace blood samples from forensic caseworks, the correct predictions (±5 years) are 91.7%. The nature of our analytical pipeline can easily be scaled up with low cost. Taken together, we propose a new age-prediction model featuring accuracy, sensitivity, high-throughput, and low cost. This model can be readily applied in both classic and newly emergent forensic contexts that require age estimation.
Age prediction
- kaggle.com
zipUpdated May 8, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMaria Frențescu (2020). Age prediction [Dataset]. https://www.kaggle.com/mariafrenti/age-predictionzip(1848481717 bytes)Available download formatsDataset updatedMay 8, 2020AuthorsMaria FrențescuDescriptionDataset
This dataset was created by Maria Frențescu
Contents
- H
Data from: An accurate pediatric bone age prediction model using deep...
- dataverse.harvard.edu
- search.dataone.org
Updated May 3, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDong Hyeok Choi, So Hyun Ahn, Rena Lee (2024). An accurate pediatric bone age prediction model using deep learning and contrast conversion [Dataset]. http://doi.org/10.7910/DVN/NMUR8XCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Unique identifierhttps://doi.org/10.7910/DVN/NMUR8XDataset updatedMay 3, 2024Dataset provided byHarvard DataverseAuthorsDong Hyeok Choi, So Hyun Ahn, Rena LeeLicenseAttribution-NonCommercial 4.0 (CC BY-NC 4.0)https://creativecommons.org/licenses/by-nc/4.0/
License information was derived automaticallyDescriptionDataset 1. 2017 RSNA AI Pediatric Bone Age Challenge. Available from: https://www.rsna.org/rsnai/ai-image-challenge/RSNA-Pediatric-Bone-Age-Challenge-2017 Dataset 2. The datasets generated during and/or analyzed during the current study
Age Prediction AV
- kaggle.com
zipUpdated Apr 23, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteGoubeast (2021). Age Prediction AV [Dataset]. https://www.kaggle.com/datasets/goubeast/age-prediction-av/discussionzip(67822884 bytes)Available download formatsDataset updatedApr 23, 2021AuthorsGoubeastDescriptionDataset
This dataset was created by Goubeast
Contents
Data from: Estimating age and age class of harvested hog deer from eye lens...
- zenodo.org
- data.niaid.nih.gov
- +1more
txtUpdated May 31, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDavid M. Forsyth; Mathieu Garel; Steve R. McLeod; David M. Forsyth; Mathieu Garel; Steve R. McLeod (2022). Data from: Estimating age and age class of harvested hog deer from eye lens mass using frequentist and Bayesian methods [Dataset]. http://doi.org/10.5061/dryad.0r31rtxtAvailable download formatsUnique identifierhttps://doi.org/10.5061/dryad.0r31rDataset updatedMay 31, 2022AuthorsDavid M. Forsyth; Mathieu Garel; Steve R. McLeod; David M. Forsyth; Mathieu Garel; Steve R. McLeodLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionEstimation of the age or age class of harvested animals is often necessary to interpret the condition and dynamics of wildlife populations. The mammalian eye lens continues to grow until death and hence the dry mass of the eye lens has commonly been used to estimate the age of mammals. The method requires the relationship between eye lens mass and age to be parameterized using individuals of known age. However, predicting age is complicated by the curvilinear relationship between eye lens mass and age. We used frequentist and Bayesian methods to predict the ages and age classes of harvested hog deer Axis porcinus from eye lens mass. Deer were tagged as calves and harvested 4–177 months later in southeastern Australia. Lenses were extracted, fixed and oven-dried. Of the five growth models evaluated, the Lord model best described the relationship between age and eye lens dry mass (R2 = 95%). The precision of age predictions obtained using the Lord model in a Bayesian mode of inference decreased with increasing eye lens dry mass, with the size of the 95% CI equaling or exceeding predicted age for hog deer > 6 years. However, most predictions of hog deer age will have reasonable precision because few animals > 6 years are harvested. Linear discriminant analysis had high predictive power for classifying hog deer to four widely-used age classes (juvenile, yearling, prime-age and senescent). The Bayesian method is recommended for inverse non-linear prediction of age and the frequentist linear discriminant analysis method is recommended for estimating age class. We provide tables of correspondence between hog deer eye lens dry mass and predicted age and age class. Our statistical methods can be used to estimate age and age class for other mammalian species, including from other ageing techniques such as tooth eruption-wear criteria.
- N
Age prediction from MRI using canonical correlation analysis and Gaussian...
- neurovault.org
niftiUpdated Nov 15, 2019+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2019). Age prediction from MRI using canonical correlation analysis and Gaussian process regression: White matter BSR values [Dataset]. http://identifiers.org/neurovault.image:305526niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:305526Dataset updatedNov 15, 2019LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescription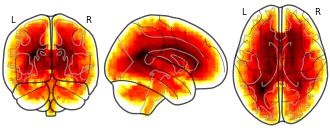
Collection description
Bootstrapped ratio (BSR) values of canonical correlation analysis (CCA) loadings from age prediction using MRI.
Subject species
homo sapiens
Modality
Structural MRI
Analysis level
group
Cognitive paradigm (task)
None / Other
Map type
Other
- m
Age prediction from DNA methylation patterns of nails
- data.mendeley.com
Updated Dec 15, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteBram Bekaert (2021). Age prediction from DNA methylation patterns of nails [Dataset]. http://doi.org/10.17632/ynm5mxmkk8.1Unique identifierhttps://doi.org/10.17632/ynm5mxmkk8.1Dataset updatedDec 15, 2021AuthorsBram BekaertLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionDNA methylation values obtained using pyrosequencing from 108 living individuals.
Abalone Age Prediction
- kaggle.com
zipUpdated Aug 26, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCitearuni kanchana (2024). Abalone Age Prediction [Dataset]. https://www.kaggle.com/datasets/arunikanchana/abalone-age-prediction/discussionzip(2395729 bytes)Available download formatsDataset updatedAug 26, 2024Authorsaruni kanchanaDescriptionDataset
This dataset was created by aruni kanchana
Contents
Data from: A clockwork fish. Age-prediction using DNA methylation-based...
- data.niaid.nih.gov
- zenodo.org
- +1more
zipUpdated Dec 9, 2019ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDafni Anastasiadi; Francesc Piferrer (2019). A clockwork fish. Age-prediction using DNA methylation-based biomarkers in the European seabass [Dataset]. http://doi.org/10.5061/dryad.m0cfxpnz4zipAvailable download formatsUnique identifierhttps://doi.org/10.5061/dryad.m0cfxpnz4Dataset updatedDec 9, 2019Dataset provided byPlant & Food Research
Institut de Ciències del MarAuthorsDafni Anastasiadi; Francesc PiferrerLicensehttps://spdx.org/licenses/CC0-1.0.htmlhttps://spdx.org/licenses/CC0-1.0.html
DescriptionAge-related changes in DNA methylation do occur. Taking advantage of this, mammalian and avian epigenetic clocks have been constructed to predict age. In fish, studies on age-related DNA methylation changes are scarce and no epigenetic clocks are available. However, in fisheries and population studies there is a need for accurate estimation of age, something that is often impossible for some economically important species with the currently available methods. Here, we used the European sea bass, a marine fish where age can be known with accuracy, to construct a piscine epigenetic clock, the first one in a cold-blooded vertebrate. We used targeted bisulfite sequencing to amplify 48 CpGs from four genes in muscle samples and applied penalized regressions to predict age. We, thus, developed an age predictor in fish that is highly accurate (0.824) and precise (2.149 years of error). In juvenile fish, accelerated growth due to elevated temperatures had no effect in age prediction, indicating that the clock is able to predict the chronological age independently of environmentally-driven perturbations. An epigenetic clock developed using muscle samples accurately predicted age in samples of testis but not ovaries, possibly reflecting the reproductive biology of fish. In conclusion, we report the development of the first piscine epigenetic clock, paving the way for similar studies in other species. Piscine epigenetic clocks should be of great utility for fisheries management and conservation purposes, where age determination is of crucial importance.
Methods Overall design: We used multiplexed bisulfite sequencing (MBS) to measure the DNA methylation of specific regions in tissues of sea bass from different age classes. Two MBS libraries were prepared and sequenced. In all cases, each tissue and age class were represented by 4 replicate fish. The first MBS library consisted of 22 valid amplicons amplified in ovary, testis and muscle of 1.28, 3.07 and 10.5 years sea bass. The second MBS library consisted of 4 valid amplicons amplified in muscle of a) 0.55, 0.96, 1, 1.1, 1.37, 1.64, 4.17, 5.83 and 6.75 years old sea bass reared at natural (low-17ºC) temperature and b) 0.48, 0.55, 0.82, 0.96, 1.1, 1.37 years old sea bass reared at high (21ºC) temperature from 7 to 68 days post fertilization.
Description of protocols: Fish were raised at the Aquarium facilities of the Institute of Marine Sciences or the Institute of Aquaculture Torre de La Sal (Spanish National Research Council, CSIC) following standard procedures until sampling. Samples were snap frozen in liquid nitrogen and kept at -80ºC until DNA extraction. Genomic DNA was extracted by the Phenol/Chlorofom/Isoamyl-alcohol (25:24:1) extraction protocol. MBS libraries were prepared as described in Anastasiadi et al 2018 (https://doi.org/10.1080/15592294.2018.1529504). Briefly, 2 μg of DNA were bisulfite-converted and PCRs with primers targeting specific bisulfite-converted regions were performed. Bead-based normalization of DNA quantities was followed by pooling of amplicons per sample. Indices were added to samples following a dual-index strategy by PCRs. Equal quantities of samples were pooled into a single final library and sequenced in an Illumina MiSeq using the 300 bp paired-end protocol.
Description of data processing: Raw reads were quality trimmed by the Trim Galore for MBS 1 and Trimmomatic for MBS 2 Trimmed reads were aligned to the reference genome dicLab (v1.0c, June 2012; http://seabass.mpipz.mpg.de/) using Bismark with --non_directional --phred33-quals --score_min L,0,-0.6. For samples of 1.28, 3.07 and 10.5 years alignments were performed in three steps: 1) paired reads were aligned, 2) unmapped reads from the first step were aligned as single reads, and 3) unpaired reads from the first step of trimming were aligned like the unmapped reads. Paired-end and single-end alignments are provided as .bam files. Methylation calling was performed by the bismark_methylation_extractor. For samples of 1.28, 3.07 and 10.5 years extraction was performed separately for paired-end and for single-end reads. Methylation files were merged into a single file containing all samples. Methylation values were read into R. CpGs with less than 5 coverage were eliminated.
In this data package, two types of data are included per sample: alignmnet files (.bam) and methylation value of each CpG (.txt). For the MBS1, paired-end and single-end alignments (.bam) are provided. The processed data files are tab-delimited and contain: 1) the name of the sample, 2) the genomic position of the CpG (in the format chr, cpg start.cpg end), 3) the percent methylation and 4) the age in years.
- f
Age estimation results obtained based on the mandible and femur separately,...
- figshare.com
- plos.figshare.com
xlsUpdated Jun 1, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteCuong Van Pham; Su-Jin Lee; So-Yeon Kim; Sookyoung Lee; Soo-Hyung Kim; Hyung-Seok Kim (2023). Age estimation results obtained based on the mandible and femur separately, and their corresponding fusion results using both male and female samples. [Dataset]. http://doi.org/10.1371/journal.pone.0251388.t002xlsAvailable download formatsUnique identifierhttps://doi.org/10.1371/journal.pone.0251388.t002Dataset updatedJun 1, 2023Dataset provided byPLOS ONEAuthorsCuong Van Pham; Su-Jin Lee; So-Yeon Kim; Sookyoung Lee; Soo-Hyung Kim; Hyung-Seok KimLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionAge estimation results obtained based on the mandible and femur separately, and their corresponding fusion results using both male and female samples.
- P
IMDB-WIKI Dataset
- paperswithcode.com
Updated Mar 23, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteRasmus Rothe; Radu Timofte; Luc van Gool (2022). IMDB-WIKI Dataset [Dataset]. https://paperswithcode.com/dataset/imdb-wiki-1Dataset updatedMar 23, 2022AuthorsRasmus Rothe; Radu Timofte; Luc van GoolDescriptionTo the best of our knowledge this is the largest publicly available dataset of face images with gender and age labels for training. We provide pretrained models for both age and gender prediction.
- F
Native American Children Facial Image Dataset
- futurebeeai.com
wavUpdated Aug 1, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteFutureBee AI (2022). Native American Children Facial Image Dataset [Dataset]. https://www.futurebeeai.com/dataset/image-dataset/facial-images-minor-native-americanwavAvailable download formatsDataset updatedAug 1, 2022Dataset provided byFutureBeeAIAuthorsFutureBee AILicensehttps://www.futurebeeai.com/data-license-agreementhttps://www.futurebeeai.com/data-license-agreement
Area coveredUnited StatesDataset funded byFutureBeeAIDescriptionIntroduction
Welcome to the Native American Child Faces Dataset, meticulously curated to enhance face recognition models and support the development of advanced biometric identification systems, child identification models, and other facial recognition technologies.
Facial Image Data
This dataset comprises over 3,000 child image sets, divided into participant-wise sets with each set including:
•Facial Images: 15 different high-quality images per child.Diversity and Representation
The dataset includes contributions from a diverse network of children across Native American countries:
•Geographical Representation: Participants from Native American countries, including USA, Canada, Mexico and more.•Demographics: Participants are children under the age of 18, representing both males and females.•File Format: The dataset contains images in JPEG and HEIC file format.Quality and Conditions
To ensure high utility and robustness, all images are captured under varying conditions:
•Lighting Conditions: Images are taken in different lighting environments to ensure variability and realism.•Backgrounds: A variety of backgrounds are available to enhance model generalization.•Device Quality: Photos are taken using the latest mobile devices to ensure high resolution and clarity.Metadata
Each facial image set is accompanied by detailed metadata for each participant, including:
•Participant Identifier•File Name•Age•Gender•Country•Demographic Information•File FormatThis metadata is essential for training models that can accurately recognize and identify children's faces across different demographics and conditions.
Usage and Applications
This facial image dataset is ideal for various applications in the field of computer vision, including but not limited to:
•Facial Recognition Models: Improving the accuracy and reliability of facial recognition systems.•KYC Models: Streamlining the identity verification processes for financial and other services.•Biometric Identity Systems: Developing robust biometric identification solutions.•Child Identification Models: Training models to accurately identify children in various scenarios.•Age Prediction Models: Training models to accurately predict the age of minors based on facial features.•Generative AI Models: Training generative AI models to create realistic and diverse synthetic facial images.Secure and Ethical Collection
•Data Security: Data was securely stored and processed within our platform, ensuring data security and confidentiality.•Ethical Guidelines: The biometric data collection process adhered to strict ethical guidelines, ensuring the privacy and consent of all participants’ guardians.•Participant Consent: The guardians were informed of the purpose of collection and potential use of the data, as agreed through written consent.Updates and
- f
Additional file 3 of Lung transcriptomic clock predicts premature aging in...
- springernature.figshare.com
txtUpdated Jun 5, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMohamed-Amin Choukrallah; Julia Hoeng; Manuel C. Peitsch; Florian Martin (2023). Additional file 3 of Lung transcriptomic clock predicts premature aging in cigarette smoke-exposed mice [Dataset]. http://doi.org/10.6084/m9.figshare.12109506.v1txtAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.12109506.v1Dataset updatedJun 5, 2023Dataset provided byfigshareAuthorsMohamed-Amin Choukrallah; Julia Hoeng; Manuel C. Peitsch; Florian MartinLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionAdditional file 3.
- F
Middle Eastern Children Facial Image Dataset
- futurebeeai.com
wavUpdated Aug 1, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteFutureBee AI (2022). Middle Eastern Children Facial Image Dataset [Dataset]. https://www.futurebeeai.com/dataset/image-dataset/facial-images-minor-middle-easternwavAvailable download formatsDataset updatedAug 1, 2022Dataset provided byFutureBeeAIAuthorsFutureBee AILicensehttps://www.futurebeeai.com/data-license-agreementhttps://www.futurebeeai.com/data-license-agreement
Dataset funded byFutureBeeAIDescriptionIntroduction
Welcome to the Middle Eastern Child Faces Dataset, meticulously curated to enhance face recognition models and support the development of advanced biometric identification systems, child identification models, and other facial recognition technologies.
Facial Image Data
This dataset comprises over 3,000 child image sets, divided into participant-wise sets with each set including:
•Facial Images: 15 different high-quality images per child.Diversity and Representation
The dataset includes contributions from a diverse network of children across Middle Eastern countries:
•Geographical Representation: Participants from Middle Eastern countries, including Egypt, Jordan, Suadi Arabia, UAE, Tunisia, and more.•Demographics: Participants are children under the age of 18, representing both males and females.•File Format: The dataset contains images in JPEG and HEIC file format.Quality and Conditions
To ensure high utility and robustness, all images are captured under varying conditions:
•Lighting Conditions: Images are taken in different lighting environments to ensure variability and realism.•Backgrounds: A variety of backgrounds are available to enhance model generalization.•Device Quality: Photos are taken using the latest mobile devices to ensure high resolution and clarity.Metadata
Each facial image set is accompanied by detailed metadata for each participant, including:
•Participant Identifier•File Name•Age•Gender•Country•Demographic Information•File FormatThis metadata is essential for training models that can accurately recognize and identify children's faces across different demographics and conditions.
Usage and Applications
This facial image dataset is ideal for various applications in the field of computer vision, including but not limited to:
•Facial Recognition Models: Improving the accuracy and reliability of facial recognition systems.•KYC Models: Streamlining the identity verification processes for financial and other services.•Biometric Identity Systems: Developing robust biometric identification solutions.•Child Identification Models: Training models to accurately identify children in various scenarios.•Age Prediction Models: Training models to accurately predict the age of minors based on facial features.•Generative AI Models: Training generative AI models to create realistic and diverse synthetic facial images.Secure and Ethical Collection
•Data Security: Data was securely stored and processed within our platform, ensuring data security and confidentiality.•Ethical Guidelines: The biometric data collection process adhered to strict ethical guidelines, ensuring the privacy and consent of all participants’ guardians.<h3 style="font-weight:•Participant Consent: The guardians were informed of the purpose of collection and potential use of the data, as agreed through written consent. - S
Diabetes Prediction in Scania - DiPiS
- snd.se
Updated Sep 12, 2013ShareFacebookTwitterEmailClick to copy linkLink copiedCiteÅke Lernmark; Helena Larsson (2013). Diabetes Prediction in Scania - DiPiS [Dataset]. https://snd.se/en/catalogue/dataset/ext0081-1Dataset updatedSep 12, 2013Dataset provided bySwedish National Data Service
Lund UniversityAuthorsÅke Lernmark; Helena LarssonLicensehttps://snd.se/en/search-and-order-data/using-datahttps://snd.se/en/search-and-order-data/using-data
Time period coveredSep 2000 - Aug 2019Area coveredSweden, Skåne CountyDescriptionDiabetes Prediction in Scania (DiPiS) aims to determine why children develop type 1 diabetes. By being able to predict which children are at risk of developing diabetes, the hope is to prevent the onset of the disease in the future. DiPiS was conducted in two stages:
Stage 1: Examination of the hereditary risk for type 1 diabetes in all newborns in Scania. This stage took place from September 2000 to September 2004. During this stage, almost 36,000 children were examined.
Stage 2: Follow-up of a group of children with hereditary risk. Approximately 5,000 children were followed. Participants in the follow-up study provided blood samples once a year and also completed a questionnaire. Children with multiple antibodies are at an increased risk of developing type 1 diabetes and were therefore monitored more frequently. The children were followed until the age of 15.
Objective: To determine factors that can predict autoimmune (type 1) diabetes in children.
DistalPhalanxOutlineAgeGroup UCR Archive Dataset
- zenodo.org
binUpdated May 14, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteZenodo (2024). DistalPhalanxOutlineAgeGroup UCR Archive Dataset [Dataset]. http://doi.org/10.5281/zenodo.11186386binAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.11186386Dataset updatedMay 14, 2024LicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis dataset is part of the UCR Archive maintained by University of Southampton researchers. Please cite a relevant or the latest full archive release if you use the datasets. See http://www.timeseriesclassification.com/.
This series of 11 classification problems were created as part of Luke Davis's PhD titled "Predictive Modelling of Bone Ageing". They are all derived from the same images, extracted from Cao et al. "Digital hand atlas and web-based bone age assessment: system design and implementation". They are designed to test the efficacy of hand and bone outline detection and whether these outlines could be helpful in bone age prediction. Algorithms to automatically extract the hand outlines and then the outlines of three bones of the middle finger (proximal, middle and distal phalanges) were applied to over 1300 images, and three human evaluators labelled the output of the image outlining as correct or incorrect. This generated three classification problems: DistalPhalanxOutlineCorrect; MiddlePhalanxOutlineCorrect; and ProximalPhalanxOutlineCorrect. The next stage of the project was to use the outlines to predict information about the subjects age. The three problems DistalPhalanxOutlineAgeGroup, MiddlePhalanxOutlineAgeGroup and ProximalPhalanxOutlineAgeGroup involve using the outline of one of the phalanges to predict whether the subject is one of three age groups: 0-6 years old, 7-12 years old and 13-19 years old. Note that these problems are aligned by subject, and hence can be treated as a multi dimensional TSC problem. Problem Phalanges contains the concatenation of all three problems. Bone age estimation is usually performed by an expert with an algorithm called Tanner-Whitehouse. This involves scoring each bone into one of seven categories based on the stage of development. The final three bone image classification problems, DistalPhalanxTW, MiddlePhalanxTW and ProximalPhalanxTW, involve predicting the Tanner-Whitehouse score (as labelled by a human expert) from the outline.
http://www.ncbi.nlm.nih.gov/pubmed/10940607
Donator: L. Davis, A. Bagnall
Data from: Brain Ages Derived from Different MRI Modalities are Associated...
- zenodo.org
- data.niaid.nih.gov
csvUpdated Aug 9, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAndrei-Claudiu Roibu; Andrei-Claudiu Roibu; Stanislaw Adaszewski; Torsten Schindler; Stephen M. Smith; Stephen M. Smith; Ana I.L. Namburete; Ana I.L. Namburete; Frederik J. Lange; Frederik J. Lange; Stanislaw Adaszewski; Torsten Schindler (2023). Brain Ages Derived from Different MRI Modalities are Associated with Distinct Biological Phenotypes [Dataset]. http://doi.org/10.5281/zenodo.8110876csvAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.8110876Dataset updatedAug 9, 2023AuthorsAndrei-Claudiu Roibu; Andrei-Claudiu Roibu; Stanislaw Adaszewski; Torsten Schindler; Stephen M. Smith; Stephen M. Smith; Ana I.L. Namburete; Ana I.L. Namburete; Frederik J. Lange; Frederik J. Lange; Stanislaw Adaszewski; Torsten SchindlerLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionAbstract
Brain ageing is a highly variable, spatially and temporally heterogeneous process, marked by numerous structural and functional changes. These can cause discrepancies between individuals’ chronological age and the apparent age of their brain, as inferred from neuroimaging data. Machine learning models, and particularly Convolutional Neural Networks (CNNs), have proven adept in capturing patterns relating to ageing induced changes in the brain. The differences between the predicted and chronological ages, referred to as brain age deltas, have emerged as useful biomarkers for exploring those factors which promote accelerated ageing or resilience, such as pathologies or lifestyle factors. However, previous studies rely only on structural neuroimaging for predictions, overlooking potentially informative functional and microstructural changes. Here we show that multiple contrasts derived from different MRI modalities can predict brain age, each encoding bespoke brain ageing information. By using 3D CNNs and UK Biobank data, we found that 57 contrasts derived from structural, susceptibility-weighted, diffusion, and functional MRI can successfully predict brain age. For each contrast, different patterns of association with non-imaging phenotypes were found, resulting in a total of 191 unique, statistically significant associations. Furthermore, we found that ensembling data from multiple contrasts results in both higher prediction accuracies and stronger correlations to non-imaging measurements. Our results demonstrate that other 3D contrasts and modalities, which have not been considered so far for the task of brain age prediction, encode different information about the ageing brain. We envision our work as being the starting point for future investigations into the causal links underpinning the observed brain age deltas and non-imaging measurement associations. For instance, drug effects can be monitored, given that certain medications correlated with accelerated brain ageing. Furthermore, continued development of brain age models could facilitate their deployment in clinical trials for recruitment and monitoring, and hospitals for diagnostic and screening tasks.
Data Description
This dataset contains the full correlation results with all nIDPs in the UK Biobank. These are presented in datasets split by sex in Female and Male subjects. For easier data manipulation, two smaller datasets have also been made available, containing just those correlation which pass the False Discovery Rate (FDR) threshold.
As experiments were also conducted for ensembles using multiple contrasts, similar datasets are provided for those.
Finally, global datasets are also provided. These are the concatenation of the associations contained in the Male and Female datasets.
Paper & Code
The original paper for this article can be accessed here:
To access the codes relevant for this project, please access the project GitHub Repos:
If using this work, please cite it based on the above paper, or using the following BibTex:
@inproceedings{roibu2023brain, title={Brain Ages Derived from Different MRI Modalities are Associated with Distinct Biological Phenotypes}, author={Roibu, Andrei-Claudiu and Adaszewski, Stanislaw and Schindler, Torsten and Smith, Stephen M and Namburete, Ana IL and Lange, Frederik J}, booktitle={2023 10th IEEE Swiss Conference on Data Science (SDS)}, pages={17--25}, year={2023}, organization={IEEE}, doi={10.1109/SDS57534.2023.00010} }Data Access
The data for this project is freely available upon application at the UK Biobank. For more information regarding the individual nIDPs, please access the UK Biobank Showcase website at: https://biobank.ctsu.ox.ac.uk/showcase/search.cgi
Funding
ACR is supported by EPSRC Grant EP/S024093/1, F. Hoffmann-La Roche AG and a 2021 Industrial Fellowship offered by the Royal Commission for the Exhibition of 1851. SMS is supported by a Wellcome Trust Collaborative Award 215573/Z/19/Z. AILN is grateful for support from the Academy of Medical Sciences under the Springboard Awards scheme (SBF005/1136), and the Bill and Melinda Gates Foundation. FJL is supported by a Wellcome Trust Collaborative Award (215573/Z/19/Z). The WIN is supported by core funding from the Wellcome Trust (203139/Z/16/Z). The computational aspects were supported by the Wellcome Trust (203141/Z/16/Z) and the NIHR Oxford BRC. Corresponding authors: ACR (andreiroibu@icloud.com), SA (stanislaw.adaszewski@roche.com) and AILN (ana.namburete@cs.ox.ac.uk).
- f
Classification tables for age group prediction.
- figshare.com
xlsxUpdated Jun 5, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteJoe L. Webb; Simon M. Moe; Andrew K. Bolstad; Elizabeth M. McNeill (2023). Classification tables for age group prediction. [Dataset]. http://doi.org/10.1371/journal.pone.0255085.s003xlsxAvailable download formatsUnique identifierhttps://doi.org/10.1371/journal.pone.0255085.s003Dataset updatedJun 5, 2023Dataset provided byPLOS ONEAuthorsJoe L. Webb; Simon M. Moe; Andrew K. Bolstad; Elizabeth M. McNeillLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis table depicts the average accuracy, F1, Precision, and Recall scores for classifying samples into their age groups. The data contained in these tables represents average scores across 1000 iterations of training/testing predictions. Each row represents a different way to select genetic features for age prediction, where each column represents the metric used for evaluating the effectiveness in age group classification. (XLSX)
- f
Data_Sheet_1_Age-specific risk factors for the prediction of obesity using a...
- frontiersin.figshare.com
pdfUpdated Jun 11, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteJunhwi Jeon; Sunmi Lee; Chunyoung Oh (2023). Data_Sheet_1_Age-specific risk factors for the prediction of obesity using a machine learning approach.pdf [Dataset]. http://doi.org/10.3389/fpubh.2022.998782.s001pdfAvailable download formatsUnique identifierhttps://doi.org/10.3389/fpubh.2022.998782.s001Dataset updatedJun 11, 2023Dataset provided byFrontiersAuthorsJunhwi Jeon; Sunmi Lee; Chunyoung OhLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionMachine Learning is a powerful tool to discover hidden information and relationships in various data-driven research fields. Obesity is an extremely complex topic, involving biological, physiological, psychological, and environmental factors. One successful approach to the topic is machine learning frameworks, which can reveal complex and essential risk factors of obesity. Over the last two decades, the obese population (BMI of above 23) in Korea has grown. The purpose of this study is to identify risk factors that predict obesity using machine learning classifiers and identify the algorithm with the best accuracy among classifiers used for obesity prediction. This work will allow people to assess obesity risk from blood tests and blood pressure data based on the KNHANES, which used data constructed by the annual survey. Our data include a total of 21,100 participants (male 10,000 and female 11,100). We assess obesity prediction by utilizing six machine learning algorithms. We explore age- and gender-specific risk factors of obesity for adults (19–79 years old). Our results highlight the four most significant features in all age-gender groups for predicting obesity: triglycerides, ALT (SGPT), glycated hemoglobin, and uric acid. Our findings show that the risk factors for obesity are sensitive to age and gender under different machine learning algorithms. Performance is highest for the 19–39 age group of both genders, with over 70% accuracy and AUC, while the 60–79 age group shows around 65% accuracy and AUC. For the 40–59 age groups, the proposed algorithm achieved over 70% in AUC, but for the female participants, it achieved lower than 70% accuracy. For all classifiers and age groups, there is no big difference in the accuracy ratio when the number of features is more than six; however, the accuracy ratio decreased in the female 19–39 age group.
- P
Abalone Dataset
- paperswithcode.com
- opendatalab.com
Updated Mar 12, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCite(2025). Abalone Dataset [Dataset]. https://paperswithcode.com/dataset/abaloneDataset updatedMar 12, 2025DescriptionPredicting the age of abalone from physical measurements. The age of abalone is determined by cutting the shell through the cone, staining it, and counting the number of rings through a microscope -- a boring and time-consuming task. Other measurements, which are easier to obtain, are used to predict the age. Further information, such as weather patterns and location (hence food availability) may be required to solve the problem.
FacebookTwitterData Sheet 1_Multiplexing and massive parallel sequencing of targeted DNA methylation to predict chronological age.docx
Attribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automatically
Estimation of chronological age is particularly informative in forensic contexts. Assessment of DNA methylation status allows for the prediction of age, though the accuracy may vary across models. In this study, we started with a carefully designed discovery cohort with more elderly subjects than other age categories, to diminish the effect of epigenetic drifting. We applied multiplexing and massive parallel sequencing of targeted DNA methylation, which let us to construct a model comprising 25 CpG sites with substantially improved accuracy (MAE = 2.279, R = 0.920). This model is further validated by an independent cohort (MAE = 2.204, 82.7% success (±5 years)). Remarkably, in a multi-center test using trace blood samples from forensic caseworks, the correct predictions (±5 years) are 91.7%. The nature of our analytical pipeline can easily be scaled up with low cost. Taken together, we propose a new age-prediction model featuring accuracy, sensitivity, high-throughput, and low cost. This model can be readily applied in both classic and newly emergent forensic contexts that require age estimation.