- a
AVSpeech: Large-scale Audio-Visual Speech Dataset
- academictorrents.com
bittorrentUpdated Jan 31, 2020 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCiteAriel Ephrat and Inbar Mosseri and Oran Lang and Tali Dekel and Kevin Wilson and Avinatan Hassidim and William T. Freeman and Michael Rubinstein (2020). AVSpeech: Large-scale Audio-Visual Speech Dataset [Dataset]. https://academictorrents.com/details/b078815ca447a3e4d17e8a2a34f13183ec5dec41bittorrent(1503015135350)Available download formatsDataset updatedJan 31, 2020Dataset authored and provided byAriel Ephrat and Inbar Mosseri and Oran Lang and Tali Dekel and Kevin Wilson and Avinatan Hassidim and William T. Freeman and Michael RubinsteinLicense
EmailClick to copy linkLink copiedCiteAriel Ephrat and Inbar Mosseri and Oran Lang and Tali Dekel and Kevin Wilson and Avinatan Hassidim and William T. Freeman and Michael Rubinstein (2020). AVSpeech: Large-scale Audio-Visual Speech Dataset [Dataset]. https://academictorrents.com/details/b078815ca447a3e4d17e8a2a34f13183ec5dec41bittorrent(1503015135350)Available download formatsDataset updatedJan 31, 2020Dataset authored and provided byAriel Ephrat and Inbar Mosseri and Oran Lang and Tali Dekel and Kevin Wilson and Avinatan Hassidim and William T. Freeman and Michael RubinsteinLicensehttps://academictorrents.com/nolicensespecifiedhttps://academictorrents.com/nolicensespecified
DescriptionAVSpeech is a new, large-scale audio-visual dataset comprising speech video clips with no interfering background noises. The segments are 3-10 seconds long, and in each clip the audible sound in the soundtrack belongs to a single speaking person, visible in the video. In total, the dataset contains roughly 4700 hours* of video segments, from a total of 290k YouTube videos, spanning a wide variety of people, languages and face poses. For more details on how we created the dataset see our paper, Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation (). * UPLOADER S NOTE: This dataset contains 3000 hours of video segments and not the entire 4700 hours. 1700 hours were not included as some no longer existed on youtube, had a copyright violation, not available in the United States, or was of poor quality. Over 1 million segments are included in this torrent, each between 3 - 10 seconds, and in 720p resolution.
- E
Laboratory Conditions Czech Audio-Visual Speech Corpus
- catalog.elra.info
- live.european-language-grid.eu
Updated Nov 5, 2008ShareFacebookTwitterEmailClick to copy linkLink copiedCiteELRA (European Language Resources Association) and its operational body ELDA (Evaluations and Language resources Distribution Agency) (2008). Laboratory Conditions Czech Audio-Visual Speech Corpus [Dataset]. http://catalog.elra.info/en-us/repository/browse/ELRA-S0283/Dataset updatedNov 5, 2008Dataset provided byELRA (European Language Resources Association) and its operational body ELDA (Evaluations and Language resources Distribution Agency)
ELRA (European Language Resources Association)Licensehttp://catalog.elra.info/static/from_media/metashare/licences/ELRA_VAR.pdfhttp://catalog.elra.info/static/from_media/metashare/licences/ELRA_VAR.pdf
http://catalog.elra.info/static/from_media/metashare/licences/ELRA_END_USER.pdfhttp://catalog.elra.info/static/from_media/metashare/licences/ELRA_END_USER.pdf
DescriptionThis is an audio-visual speech database for training and testing of Czech audio-visual continuous speech recognition systems. The corpus consists of about 25 hours of audio-visual records of 65 speakers in laboratory conditions. Data collection was done with static illumination, and recorded subjects were instructed to remain static.The average speaker age was 22 years old. Speakers were asked to read 200 sentences each (50 common for all speakers and 150 specific to each speaker). The average total length of recording per speaker is 23 minutes.All audio-visual data are transcribed (.trs files) and divided into sentences (one sentence per file). For each video file we get the description file containing information about the position and size of the region of interest.Acoustic data are stored in wave files using PCM format, sampling frequency 44kHz, resolution 16 bits. Each speaker’s acoustic data set represents about 140 MB of disk space (about 9 GB as a whole).Visual data are stored in video files (.avi format) using the digital video (DV) codec. Visual data per speaker take about 3 GB of disk (about 195 GB as a whole) and are stored on an IDE hard disk (NTFS format).
The Grid Audio-Visual Speech Corpus
- zenodo.org
- live.european-language-grid.eu
pdf, zipUpdated Jul 22, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMartin Cooke; Jon Barker; Stuart Cunningham; Xu Shao; Martin Cooke; Jon Barker; Stuart Cunningham; Xu Shao (2024). The Grid Audio-Visual Speech Corpus [Dataset]. http://doi.org/10.5281/zenodo.3625687zip, pdfAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.3625687Dataset updatedJul 22, 2024AuthorsMartin Cooke; Jon Barker; Stuart Cunningham; Xu Shao; Martin Cooke; Jon Barker; Stuart Cunningham; Xu ShaoLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThe Grid Corpus is a large multitalker audiovisual sentence corpus designed to support joint computational-behavioral studies in speech perception. In brief, the corpus consists of high-quality audio and video (facial) recordings of 1000 sentences spoken by each of 34 talkers (18 male, 16 female), for a total of 34000 sentences. Sentences are of the form "put red at G9 now".
audio_25k.zip contains the wav format utterances at a 25 kHz sampling rate in a separate directory per talker
alignments.zip provides word-level time alignments, again separated by talker
s1.zip, s2.zip etc contain .jpg videos for each talker [note that due to an oversight, no video for talker t21 is available]The Grid Corpus is described in detail in the paper jasagrid.pdf included in the dataset.
- E
Czech Audio-Visual Speech Corpus for Recognition with Impaired Conditions
- catalogue.elra.info
- live.european-language-grid.eu
Updated Nov 5, 2008ShareFacebookTwitterEmailClick to copy linkLink copiedCiteELRA (European Language Resources Association) and its operational body ELDA (Evaluations and Language resources Distribution Agency) (2008). Czech Audio-Visual Speech Corpus for Recognition with Impaired Conditions [Dataset]. https://catalogue.elra.info/en-us/repository/browse/ELRA-S0284/Dataset updatedNov 5, 2008Dataset provided byELRA (European Language Resources Association) and its operational body ELDA (Evaluations and Language resources Distribution Agency)
ELRA (European Language Resources Association)Licensehttps://catalogue.elra.info/static/from_media/metashare/licences/ELRA_END_USER.pdfhttps://catalogue.elra.info/static/from_media/metashare/licences/ELRA_END_USER.pdf
https://catalogue.elra.info/static/from_media/metashare/licences/ELRA_VAR.pdfhttps://catalogue.elra.info/static/from_media/metashare/licences/ELRA_VAR.pdf
DescriptionThis is an audio-visual speech database for training and testing of Czech audio-visual continuous speech recognition systems collected with impaired illumination conditions. The corpus consists of about 20 hours of audio-visual records of 50 speakers in laboratory conditions. Recorded subjects were instructed to remain static. The illumination varied and chunks of each speaker were recorded with several different conditions, such as full illumination, or illumination from one side (left or right) only. These conditions make the database usable for training lip-/head-tracking systems under various illumination conditions independently of the language. Speakers were asked to read 200 sentences each (50 common for all speakers and 150 specific to each speaker). The average total length of recording per speaker was 23 minutes.Acoustic data are stored in wave files using PCM format, sampling frequency 44kHz, resolution 16 bits. Each speaker’s acoustic data set represents about 180 MB of disk space (about 8.8 GB).Visual data are stored in video files (.avi format) using the digital video (DV) codec. Visual data per speaker take about 3.7 GB of disk (about 185 GB as a whole) and are stored on an IDE hard disk (NTFS format).
- F
Audio Visual Speech Dataset: Korean
- futurebeeai.com
wavUpdated Aug 1, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteFutureBee AI (2022). Audio Visual Speech Dataset: Korean [Dataset]. https://www.futurebeeai.com/dataset/multi-modal-dataset/korean-visual-speech-datasetwavAvailable download formatsDataset updatedAug 1, 2022Dataset provided byFutureBeeAIAuthorsFutureBee AILicensehttps://www.futurebeeai.com/policies/ai-data-license-agreementhttps://www.futurebeeai.com/policies/ai-data-license-agreement
Dataset funded byFutureBeeAIDescriptionIntroduction
Welcome to the Korean Language Visual Speech Dataset! This dataset is a collection of diverse, single-person unscripted spoken videos supporting research in visual speech recognition, emotion detection, and multimodal communication.
Dataset Content
This visual speech dataset contains 1000 videos in Korean language each paired with a corresponding high-fidelity audio track. Each participant is answering a specific question in a video in an unscripted and spontaneous nature.
•Participant Diversity:•Speakers: The dataset includes visual speech data from more than 200 participants from different states/provinces of South Korea.•Regions: Ensures a balanced representation of Skip 3 accents, dialects, and demographics.•Participant Profile: Participants range from 18 to 70 years old, representing both males and females in a 60:40 ratio, respectively.Video Data
While recording each video extensive guidelines are kept in mind to maintain the quality and diversity.
•Recording Details:•File Duration: Average duration of 30 seconds to 3 minutes per video.•Formats: Videos are available in MP4 or MOV format.•Resolution: Videos are recorded in ultra-high-definition resolution with 30 fps or above.•Device: Both the latest Android and iOS devices are used in this collection.•Recording Conditions: Videos were recorded under various conditions to ensure diversity and reduce bias:•Indoor and Outdoor Settings: Includes both indoor and outdoor recordings.•Lighting Variations: Captures videos in daytime, nighttime, and varying lighting conditions.•Camera Positions: Includes handheld and fixed camera positions, as well as portrait and landscape orientations.•Face Orientation: Contains straight face and tilted face angles.•Participant Positions: Records participants in both standing and seated positions.•Motion Variations: Features both stationary and moving videos, where participants pass through different lighting conditions.•Occlusions: Includes videos where the participant's face is partially occluded by hand movements, microphones, hair, glasses, and facial hair.•Focus: In each video, the participant's face remains in focus throughout the video duration, ensuring the face stays within the video frame.•Video Content: In each video, the participant answers a specific question in an unscripted manner. These questions are designed to capture various emotions of participants. The dataset contain videos expressing following human emotions:•Happy•Sad•Excited•Angry•Annoyed•Normal•Question Diversity: For each human emotion participant answered a specific question expressing that particular emotion.Metadata
The dataset provides comprehensive metadata for each video recording and participant:
• - F
Audio Visual Speech Dataset: German
- futurebeeai.com
wavUpdated Aug 1, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteFutureBee AI (2022). Audio Visual Speech Dataset: German [Dataset]. https://www.futurebeeai.com/dataset/multi-modal-dataset/german-visual-speech-datasetwavAvailable download formatsDataset updatedAug 1, 2022Dataset provided byFutureBeeAIAuthorsFutureBee AILicensehttps://www.futurebeeai.com/policies/ai-data-license-agreementhttps://www.futurebeeai.com/policies/ai-data-license-agreement
Dataset funded byFutureBeeAIDescriptionIntroduction
Welcome to the German Language Visual Speech Dataset! This dataset is a collection of diverse, single-person unscripted spoken videos supporting research in visual speech recognition, emotion detection, and multimodal communication.
Dataset Content
This visual speech dataset contains 1000 videos in German language each paired with a corresponding high-fidelity audio track. Each participant is answering a specific question in a video in an unscripted and spontaneous nature.
•Participant Diversity:•Speakers: The dataset includes visual speech data from more than 200 participants from different states/provinces of Germany.•Regions: Ensures a balanced representation of Skip 3 accents, dialects, and demographics.•Participant Profile: Participants range from 18 to 70 years old, representing both males and females in a 60:40 ratio, respectively.Video Data
While recording each video extensive guidelines are kept in mind to maintain the quality and diversity.
•Recording Details:•File Duration: Average duration of 30 seconds to 3 minutes per video.•Formats: Videos are available in MP4 or MOV format.•Resolution: Videos are recorded in ultra-high-definition resolution with 30 fps or above.•Device: Both the latest Android and iOS devices are used in this collection.•Recording Conditions: Videos were recorded under various conditions to ensure diversity and reduce bias:•Indoor and Outdoor Settings: Includes both indoor and outdoor recordings.•Lighting Variations: Captures videos in daytime, nighttime, and varying lighting conditions.•Camera Positions: Includes handheld and fixed camera positions, as well as portrait and landscape orientations.•Face Orientation: Contains straight face and tilted face angles.•Participant Positions: Records participants in both standing and seated positions.•Motion Variations: Features both stationary and moving videos, where participants pass through different lighting conditions.•Occlusions: Includes videos where the participant's face is partially occluded by hand movements, microphones, hair, glasses, and facial hair.•Focus: In each video, the participant's face remains in focus throughout the video duration, ensuring the face stays within the video frame.•Video Content: In each video, the participant answers a specific question in an unscripted manner. These questions are designed to capture various emotions of participants. The dataset contain videos expressing following human emotions:•Happy•Sad•Excited•Angry•Annoyed•Normal•Question Diversity: For each human emotion participant answered a specific question expressing that particular emotion.Metadata
The dataset provides comprehensive metadata for each video recording and participant:
• - h
AVE-Speech
- huggingface.co
Updated Jan 25, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMulti-Modal Learning Group (2025). AVE-Speech [Dataset]. https://huggingface.co/datasets/MML-Group/AVE-SpeechDataset updatedJan 25, 2025Dataset authored and provided byMulti-Modal Learning GroupLicenseAttribution-NonCommercial-ShareAlike 4.0 (CC BY-NC-SA 4.0)https://creativecommons.org/licenses/by-nc-sa/4.0/
License information was derived automaticallyDescriptionAVE Speech: A Comprehensive Multi-Modal Dataset for Speech Recognition Integrating Audio, Visual, and Electromyographic Signals
AbstractAVE Speech is a large-scale Mandarin speech corpus that pairs synchronized audio, lip video and surface electromyography (EMG) recordings. The dataset contains 100 sentences read by 100 native speakers. Each participant repeated the full corpus ten times, yielding over 55 hours of data per modality. These complementary signals enable… See the full description on the dataset page: https://huggingface.co/datasets/MML-Group/AVE-Speech.
- r
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS)
- resodate.org
- service.tib.eu
Updated Dec 3, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteSteven R Livingstone; Frank A Russo (2024). The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) [Dataset]. https://resodate.org/resources/aHR0cHM6Ly9zZXJ2aWNlLnRpYi5ldS9sZG1zZXJ2aWNlL2RhdGFzZXQvdGhlLXJ5ZXJzb24tYXVkaW8tdmlzdWFsLWRhdGFiYXNlLW9mLWVtb3Rpb25hbC1zcGVlY2gtYW5kLXNvbmctLXJhdmRlc3MtDataset updatedDec 3, 2024Dataset provided byLeibniz Data ManagerAuthorsSteven R Livingstone; Frank A RussoDescriptionA dynamic, multi-modal set of facial and vocal expressions in North American English
- t
AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation
- service.tib.eu
Updated Jan 3, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCite(2025). AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation [Dataset]. https://service.tib.eu/ldmservice/dataset/av2av--direct-audio-visual-speech-to-audio-visual-speech-translationDataset updatedJan 3, 2025DescriptionThe proposed AV2AV framework can translate spoken languages in a many-to-many setting without text.
- f
Audio-Visual Speech Cue Combination
- plos.figshare.com
qtUpdated Jun 2, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDerek H. Arnold; Morgan Tear; Ryan Schindel; Warrick Roseboom (2023). Audio-Visual Speech Cue Combination [Dataset]. http://doi.org/10.1371/journal.pone.0010217qtAvailable download formatsUnique identifierhttps://doi.org/10.1371/journal.pone.0010217Dataset updatedJun 2, 2023Dataset provided byPLOS ONEAuthorsDerek H. Arnold; Morgan Tear; Ryan Schindel; Warrick RoseboomLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionBackgroundDifferent sources of sensory information can interact, often shaping what we think we have seen or heard. This can enhance the precision of perceptual decisions relative to those made on the basis of a single source of information. From a computational perspective, there are multiple reasons why this might happen, and each predicts a different degree of enhanced precision. Relatively slight improvements can arise when perceptual decisions are made on the basis of multiple independent sensory estimates, as opposed to just one. These improvements can arise as a consequence of probability summation. Greater improvements can occur if two initially independent estimates are summated to form a single integrated code, especially if the summation is weighted in accordance with the variance associated with each independent estimate. This form of combination is often described as a Bayesian maximum likelihood estimate. Still greater improvements are possible if the two sources of information are encoded via a common physiological process.Principal FindingsHere we show that the provision of simultaneous audio and visual speech cues can result in substantial sensitivity improvements, relative to single sensory modality based decisions. The magnitude of the improvements is greater than can be predicted on the basis of either a Bayesian maximum likelihood estimate or a probability summation.ConclusionOur data suggest that primary estimates of speech content are determined by a physiological process that takes input from both visual and auditory processing, resulting in greater sensitivity than would be possible if initially independent audio and visual estimates were formed and then subsequently combined.
- Z
Enhanced RAVDESS Speech Dataset
- data.niaid.nih.gov
- zenodo.org
Updated Oct 2, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCitePardo, Bryan (2021). Enhanced RAVDESS Speech Dataset [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_4783520Dataset updatedOct 2, 2021Dataset provided byMorrison, Max
Caceres, Juan-Pablo
Pardo, Bryan
Jin, Zeyu
Bryan, Nicholas J.LicenseAttribution-NonCommercial-ShareAlike 4.0 (CC BY-NC-SA 4.0)https://creativecommons.org/licenses/by-nc-sa/4.0/
License information was derived automaticallyDescriptionThis is a modified version of the speech audio contained within the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) dataset. The original dataset can be found here. The unmodified version of just the speech audio used as source material for this dataset can be found here. This dataset performs speech enhancement and bandwidth extension on the original speech using HiFi-GAN. HiFi-GAN produces high-quality speech at 48 kHz that contains significantly less noise and reverb relative to the original recordings.
If you use this work as part of an academic publication, please cite the papers corresponding to both the original dataset as well as HiFi-GAN:
Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391.
Su, Jiaqi, Zeyu Jin, and Adam Finkelstein. "HiFi-GAN: High-fidelity denoising and dereverberation based on speech deep features in adversarial networks." Proc. Interspeech. October 2020.
Note that there are two recent papers with the name "HiFi-GAN". Please be sure to cite the correct paper as listed here.
- F
Audio Visual Speech Dataset: Indian English
- futurebeeai.com
wavUpdated Aug 1, 2022+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteFutureBee AI (2022). Audio Visual Speech Dataset: Indian English [Dataset]. https://www.futurebeeai.com/dataset/multi-modal-dataset/indian-english-visual-speech-datasetwavAvailable download formatsDataset updatedAug 1, 2022Dataset provided byFutureBeeAIAuthorsFutureBee AILicensehttps://www.futurebeeai.com/policies/ai-data-license-agreementhttps://www.futurebeeai.com/policies/ai-data-license-agreement
Dataset funded byFutureBeeAIDescriptionIntroduction
Welcome to the Indian English Language Visual Speech Dataset! This dataset is a collection of diverse, single-person unscripted spoken videos supporting research in visual speech recognition, emotion detection, and multimodal communication.
Dataset Content
This visual speech dataset contains 1000 videos in Indian English language each paired with a corresponding high-fidelity audio track. Each participant is answering a specific question in a video in an unscripted and spontaneous nature.
•Participant Diversity:•Speakers: The dataset includes visual speech data from more than 200 participants from different states/provinces of India.•Regions: Ensures a balanced representation of Skip 3 accents, dialects, and demographics.•Participant Profile: Participants range from 18 to 70 years old, representing both males and females in a 60:40 ratio, respectively.Video Data
While recording each video extensive guidelines are kept in mind to maintain the quality and diversity.
•Recording Details:•File Duration: Average duration of 30 seconds to 3 minutes per video.•Formats: Videos are available in MP4 or MOV format.•Resolution: Videos are recorded in ultra-high-definition resolution with 30 fps or above.•Device: Both the latest Android and iOS devices are used in this collection.•Recording Conditions: Videos were recorded under various conditions to ensure diversity and reduce bias:•Indoor and Outdoor Settings: Includes both indoor and outdoor recordings.•Lighting Variations: Captures videos in daytime, nighttime, and varying lighting conditions.•Camera Positions: Includes handheld and fixed camera positions, as well as portrait and landscape orientations.•Face Orientation: Contains straight face and tilted face angles.•Participant Positions: Records participants in both standing and seated positions.•Motion Variations: Features both stationary and moving videos, where participants pass through different lighting conditions.•Occlusions: Includes videos where the participant's face is partially occluded by hand movements, microphones, hair, glasses, and facial hair.•Focus: In each video, the participant's face remains in focus throughout the video duration, ensuring the face stays within the video frame.•Video Content: In each video, the participant answers a specific question in an unscripted manner. These questions are designed to capture various emotions of participants. The dataset contain videos expressing following human emotions:•Happy•Sad•Excited•Angry•Annoyed•Normal•Question Diversity: For each human emotion participant answered a specific question expressing that particular emotion.Metadata
The dataset provides comprehensive metadata for each video recording and participant:
• - t
Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR)
- service.tib.eu
Updated Nov 25, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2024). Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR) [Dataset]. https://service.tib.eu/ldmservice/dataset/cantonese-in-car-audio-visual-speech-recognition--ci-avsr-Dataset updatedNov 25, 2024DescriptionCantonese In-car Audio-Visual Speech Recognition (CI-AVSR) is a multimodal dataset that consists of 4,984 samples of in-car commands in the Cantonese language, combining audio and visual components, aimed to improve in-car command recognition.
- f
Audio Visual Database for Speech Disfluency
- figshare.com
zipUpdated Apr 2, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteShamika Likhite (2024). Audio Visual Database for Speech Disfluency [Dataset]. http://doi.org/10.6084/m9.figshare.25526953.v1zipAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.25526953.v1Dataset updatedApr 2, 2024Dataset provided byfigshareAuthorsShamika LikhiteLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis is a database for Multimodal Speech Disfluency. The Fluency Bank dataset comprises stuttering event annotations for 34 video podcasts, containing approximately 4000 audio and video clips, each lasting 3 seconds. Audio and Video files are part of this dataset and full episodes can also be downloaded using url in fluencybank_episodes.csv.
- H
PAVSig: Polish multichannel Audio-Visual child speech dataset with...
- dataverse.harvard.edu
Updated Aug 26, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMichal Krecichwost (2025). PAVSig: Polish multichannel Audio-Visual child speech dataset with double-expert Sigmatism diagnosis [Dataset]. http://doi.org/10.7910/DVN/IHZRGBCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Unique identifierhttps://doi.org/10.7910/DVN/IHZRGBDataset updatedAug 26, 2025Dataset provided byHarvard DataverseAuthorsMichal KrecichwostLicensehttps://dataverse.harvard.edu/api/datasets/:persistentId/versions/1.0/customlicense?persistentId=doi:10.7910/DVN/IHZRGBhttps://dataverse.harvard.edu/api/datasets/:persistentId/versions/1.0/customlicense?persistentId=doi:10.7910/DVN/IHZRGB
DescriptionThe paper introduces PAVSig: Polish Audio-Visual child speech dataset for computer-aided diagnosis of Sigmatism (lisp). The study aimed to gather data on articulation, acoustics, and visual appearance of the articulators in normal and distorted child speech, particularly in sigmatism. The data was collected in 2021-2023 in six kindergarten and school facilities in Poland during the speech therapy examinations of 201 children aged 4-8. The diagnosis was performed simultaneously with data recording, including 15-channel spatial audio signals and a dual-camera stereovision stream of the speaker's oral region. The data record comprises audiovisual recordings of 51 words and 17 logotomes containing all 12 Polish sibilants and the corresponding speech therapy diagnoses from two independent speech therapy experts. In total, we share 66,781 audio-video segments, including 12,830 words and 53,951 phonemes (12,576 sibilants).
GRID/CHiME-2 Track 1 - Video Features (25ms, 10ms)
- zenodo.org
- live.european-language-grid.eu
application/gzipUpdated Jan 24, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteHendrik Meutzner; Hendrik Meutzner (2020). GRID/CHiME-2 Track 1 - Video Features (25ms, 10ms) [Dataset]. http://doi.org/10.5281/zenodo.260211application/gzipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.260211Dataset updatedJan 24, 2020AuthorsHendrik Meutzner; Hendrik MeutznerLicenseAttribution-NonCommercial 4.0 (CC BY-NC 4.0)https://creativecommons.org/licenses/by-nc/4.0/
License information was derived automaticallyDescriptionThis archive contains the video features in Kaldi's [1] ark format that correspond to the CHiME-2 Track 1 [2] utterances for the isolated data (train, devel, test).
The video files have been taken from the GRID corpus [3,4]. The features contain the 63-dimensional DCT coefficients of the landmark points extracted using the Viola-Jones algorithm. The features have been end-pointed and interpolated using a differential digital analyser in order to match the length of the utterances when using a frame length of 25ms and a frame shift of 10ms, which is the default configuration of Kaldi's feature extraction scripts.
[2] http://spandh.dcs.shef.ac.uk/chime_challenge/chime2013/chime2_task1.html
[3] http://spandh.dcs.shef.ac.uk/gridcorpus
[4] Martin Cooke, Jon Barker, and Stuart Cunningham and Xu Shao, "An audio-visual corpus for speech perception and automatic speech recognition", The Journal of the Acoustical Society of America 120, 2421 (2006); http://doi.org/10.1121/1.2229005
- O
AVSpeech
- opendatalab.com
zipUpdated May 2, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteHebrew University of Jerusalem (2023). AVSpeech [Dataset]. https://opendatalab.com/OpenDataLab/AVSpeechzipAvailable download formatsDataset updatedMay 2, 2023Dataset provided byGoogle Research
Hebrew University of JerusalemLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionAVSpeech is a large-scale audio-visual dataset comprising speech clips with no interfering background signals. The segments are of varying length, between 3 and 10 seconds long, and in each clip the only visible face in the video and audible sound in the soundtrack belong to a single speaking person. In total, the dataset contains roughly 4700 hours of video segments with approximately 150,000 distinct speakers, spanning a wide variety of people, languages and face poses.
- r
Resource Management Audio-Visual (RMAV) dataset
- resodate.org
- service.tib.eu
Updated Dec 16, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteHelen L Bear; Richard Harvey (2024). Resource Management Audio-Visual (RMAV) dataset [Dataset]. https://resodate.org/resources/aHR0cHM6Ly9zZXJ2aWNlLnRpYi5ldS9sZG1zZXJ2aWNlL2RhdGFzZXQvcmVzb3VyY2UtbWFuYWdlbWVudC1hdWRpby12aXN1YWwtLXJtYXYtLWRhdGFzZXQ=Dataset updatedDec 16, 2024Dataset provided byLeibniz Data ManagerAuthorsHelen L Bear; Richard HarveyDescriptionThe RMAV dataset consists of 20 British English speakers up to 200 utterances per speaker of the Resource Management (RM) sentences.
- u
Data from: Detection and Recognition of Asynchronous Auditory/Visual Speech:...
- drum.lib.umd.edu
Updated Jan 4, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteGordon-Salant, Sandra; Schwartz, Maya; Oppler, Kelsey; Yeni-Komshian, Grace (2022). Detection and Recognition of Asynchronous Auditory/Visual Speech: Effects of Age, Hearing Loss, and Talker Accent [Dataset]. http://doi.org/10.13016/iwmd-dvuxUnique identifierhttps://doi.org/10.13016/iwmd-dvuxDataset updatedJan 4, 2022AuthorsGordon-Salant, Sandra; Schwartz, Maya; Oppler, Kelsey; Yeni-Komshian, GraceLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyTime period coveredJan 2022DescriptionThis investigation examined age-related differences in auditory-visual (AV) integration as reflected on perceptual judgments of temporally misaligned AV English sentences spoken by native English and native Spanish talkers. In the detection task, it was expected that slowed auditory temporal processing of older participants, relative to younger participants, would be manifest as a shift in the range over which participants would judge asynchronous stimuli as synchronous (referred to as the “AV simultaneity window”). The older participants were also expected to exhibit greater declines in speech recognition for asynchronous AV stimuli than younger participants. Talker accent was hypothesized to influence listener performance, with older listeners exhibiting a greater narrowing of the AV simultaneity window and much poorer recognition of asynchronous AV foreign-accented speech compared to younger listeners. Participant groups included younger and older participants with normal hearing and older participants with hearing loss. Stimuli were video recordings of sentences produced by native English and native Spanish talkers. The video recordings were altered in 50 ms steps by delaying either the audio or video onset. Participants performed a detection task in which the judged whether the sentences were synchronous or asynchronous, and performed a recognition task for multiple synchronous and asynchronous conditions. Both the detection and recognition tasks were conducted at the individualized signal-to-noise ratio (SNR) corresponding to approximately 70% correct speech recognition performance for synchronous AV sentences. Older listeners with and without hearing loss generally showed wider AV simultaneity windows than younger listeners, possibly reflecting slowed auditory temporal processing in auditory lead conditions and reduced sensitivity to asynchrony in auditory lag conditions. However, older and younger listeners were affected similarly by misalignment of auditory and visual signal onsets on the speech recognition task. This suggests that older listeners are negatively impacted by temporal misalignments for speech recognition, even when they do not notice that the stimuli are asynchronous. Overall, the findings show that when listener performance is equated for simultaneous AV speech signals, age effects are apparent in detection judgments but not in recognition of asynchronous speech.
- N
AV speech with speech and face regressors - MNQZW: logicalAndAll
- neurovault.org
niftiUpdated Sep 10, 2020+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2020). AV speech with speech and face regressors - MNQZW: logicalAndAll [Dataset]. http://identifiers.org/neurovault.image:404929niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:404929Dataset updatedSep 10, 2020LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescription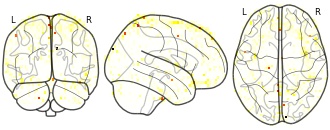
Collection description
contrast for any main character speech and face vs all else w face and speech regressors
Subject species
homo sapiens
Modality
fMRI-BOLD
Analysis level
group
Cognitive paradigm (task)
None / Other
Map type
V
FacebookTwitterAVSpeech: Large-scale Audio-Visual Speech Dataset
https://academictorrents.com/nolicensespecifiedhttps://academictorrents.com/nolicensespecified
AVSpeech is a new, large-scale audio-visual dataset comprising speech video clips with no interfering background noises. The segments are 3-10 seconds long, and in each clip the audible sound in the soundtrack belongs to a single speaking person, visible in the video. In total, the dataset contains roughly 4700 hours* of video segments, from a total of 290k YouTube videos, spanning a wide variety of people, languages and face poses. For more details on how we created the dataset see our paper, Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation (). * UPLOADER S NOTE: This dataset contains 3000 hours of video segments and not the entire 4700 hours. 1700 hours were not included as some no longer existed on youtube, had a copyright violation, not available in the United States, or was of poor quality. Over 1 million segments are included in this torrent, each between 3 - 10 seconds, and in 720p resolution.