- h
coco2017
- huggingface.co
 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCitePhilipp, coco2017 [Dataset]. https://huggingface.co/datasets/phiyodr/coco2017CroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.AuthorsPhilippDescription
EmailClick to copy linkLink copiedCitePhilipp, coco2017 [Dataset]. https://huggingface.co/datasets/phiyodr/coco2017CroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.AuthorsPhilippDescriptioncoco2017
Image-text pairs from MS COCO2017.
Data originData originates from cocodataset.org While coco-karpathy uses a dense format (with several sentences and sendids per row), coco-karpathy-long uses a long format with one sentence (aka caption) and sendid per row. coco-karpathy-long uses the first five sentences and therefore is five times as long as coco-karpathy. phiyodr/coco2017: One row corresponds one image with several sentences. phiyodr/coco2017-long: One row… See the full description on the dataset page: https://huggingface.co/datasets/phiyodr/coco2017.
Data from: Mushroom classification
- kaggle.com
Updated Feb 4, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMathieu DUVERNE (2024). Mushroom classification [Dataset]. https://www.kaggle.com/datasets/mathieuduverne/mushroom-classificationCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedFeb 4, 2024AuthorsMathieu DUVERNELicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThe dataset includes 8857 images. Mushroom are annotated in COCO format.
The following pre-processing was applied to each image: * Auto-orientation of pixel data (with EXIF-orientation stripping) * Resize to 640x640 (Stretch)
The following augmentation was applied to create 3 versions of each source image: * 50% probability of horizontal flip * 50% probability of vertical flip
The structure:
dataset-directory/ ├─ README.dataset.txt ├─ README.roboflow.txt ├─ train │ ├─ train-image-1.jpg │ ├─ train-image-1.jpg │ ├─ ... │ └─ _annotations.coco.json ├─ test │ ├─ test-image-1.jpg │ ├─ test-image-1.jpg │ ├─ ... │ └─ _annotations.coco.json └─ valid ├─ valid-image-1.jpg ├─ valid-image-1.jpg ├─ ... └─ _annotations.coco.jsonTo convert the format to YOLO annotations, go to roboflow.
- h
llava-bench-coco
- huggingface.co
Updated Apr 21, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteLMMs-Lab (2024). llava-bench-coco [Dataset]. https://huggingface.co/datasets/lmms-lab/llava-bench-cocoCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedApr 21, 2024Dataset authored and provided byLMMs-LabDescriptionLarge-scale Multi-modality Models Evaluation Suite
Accelerating the development of large-scale multi-modality models (LMMs) with lmms-eval
🏠 Homepage | 📚 Documentation | 🤗 Huggingface Datasets
This DatasetThis is a formatted version of LLaVA-Bench(COCO) that is used in LLaVA. It is used in our lmms-eval pipeline to allow for one-click evaluations of large multi-modality models. @misc{liu2023improvedllava, author={Liu, Haotian and Li, Chunyuan and… See the full description on the dataset page: https://huggingface.co/datasets/lmms-lab/llava-bench-coco.
Data from: Dataset of very-high-resolution satellite RGB images to train...
- zenodo.org
- produccioncientifica.ugr.es
zipUpdated Jul 6, 2022+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteRohaifa Khaldi; Rohaifa Khaldi; Sergio Puertas; Sergio Puertas; Siham Tabik; Siham Tabik; Domingo Alcaraz-Segura; Domingo Alcaraz-Segura (2022). Dataset of very-high-resolution satellite RGB images to train deep learning models to detect and segment high-mountain juniper shrubs in Sierra Nevada (Spain) [Dataset]. http://doi.org/10.5281/zenodo.6793457zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.6793457Dataset updatedJul 6, 2022AuthorsRohaifa Khaldi; Rohaifa Khaldi; Sergio Puertas; Sergio Puertas; Siham Tabik; Siham Tabik; Domingo Alcaraz-Segura; Domingo Alcaraz-SeguraLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyArea coveredSpain, Sierra NevadaDescriptionThis dataset provides annotated very-high-resolution satellite RGB images extracted from Google Earth to train deep learning models to perform instance segmentation of Juniperus communis L. and Juniperus sabina L. shrubs. All images are from the high mountain of Sierra Nevada in Spain. The dataset contains 810 images (.jpg) of size 224x224 pixels. We also provide partitioning of the data into Train (567 images), Test (162 images), and Validation (81 images) subsets. Their annotations are provided in three different .json files following the COCO annotation format.
The Digital Forensics 2023 dataset - DF2023
- zenodo.org
- data.niaid.nih.gov
Updated Apr 3, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDavid Fischinger; David Fischinger; Martin Boyer; Martin Boyer (2025). The Digital Forensics 2023 dataset - DF2023 [Dataset]. http://doi.org/10.5281/zenodo.7326540Unique identifierhttps://doi.org/10.5281/zenodo.7326540Dataset updatedApr 3, 2025AuthorsDavid Fischinger; David Fischinger; Martin Boyer; Martin BoyerLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionFor a detailed description of the DF2023 dataset, please refer to:
@inproceedings{Fischinger2023DFNet, title={DF2023: The Digital Forensics 2023 Dataset for Image Forgery Detection}, author={David Fischinger and Martin Boyer}, journal={The 25th Irish Machine Vision and Image Processing conference. (IMVIP)}, year={2023} }DF2023 is a dataset for image forgery detection and localization. The training and validation datasets contain 1,000,000/5,000 manipulated images (and the ground truth masks).
The DF2023 training dataset comprises:
- 100K forged images produced by removal (inpainting) operations
- 200K images produced by enhancement modifications
- 300K copy-move manipulated images and
- 400K spliced images
=== Naming convention ===
The naming convention of DF2023 encodes information about the applied manipulations. Each image name has the following form:
COCO_DF_0123456789_NNNNNNNN.{EXT} (e.g. COCO_DF_E000G40117_00200620.jpg)
After the identifier of the image data source ("COCO") and the self-reference to the Digital Forensics ("DF") dataset, there are 10 digits as placeholders for the manipulation. Position 0 defines the manipulation types copy-move, splicing, removal, enhancement ([C,S,R,E]). The following digits 1-9 represent donor patch manipulations. For positions [1,2,7,8] (resample, flip, noise and brightness), a binary value indicates if this manipulation was applied to the donor image patch. Position 3 (rotate) indicates by the values 0-3 if the rotation was executed by 0, 90, 180 or 270 degrees. Position 4 defines if BoxBlur (B) or GaussianBlur (G) was used. Position 5 specifies the blurring radius. A value of 0 indicates that no blurring was executed. Position 6 indicates which of the Python-PIL contrast filters EDGE ENHANCE, EDGE ENHANCE MORE, SHARPEN, UnsharpMask or ImageEnhance (values 1-5) was applied. If none of them was applied, this value is set to 0. Finally, position 9 is set to the JPEG compression factor modulo 10, a value of 0 indicates that no JPEG compression was applied. The 8 characters NNNNNNNN in the image name template stand for a running number of the images.
=== Terms of Use / Licence ===
The DF2023 dataset is based on the MS COCO dataset. Therefore, rules for using the images form MS COCO apply also for DF2023:
Images
The COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.
YOGData: Labelled data (YOLO and Mask R-CNN) for yogurt cup identification...
- zenodo.org
- explore.openaire.eu
- +1more
bin, zipUpdated Jun 29, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteSymeon Symeonidis; Vasiliki Balaska; Dimitrios Tsilis; Fotis K. Konstantinidis; Fotis K. Konstantinidis; Symeon Symeonidis; Vasiliki Balaska; Dimitrios Tsilis (2022). YOGData: Labelled data (YOLO and Mask R-CNN) for yogurt cup identification within production lines [Dataset]. http://doi.org/10.5281/zenodo.6773531bin, zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.6773531Dataset updatedJun 29, 2022AuthorsSymeon Symeonidis; Vasiliki Balaska; Dimitrios Tsilis; Fotis K. Konstantinidis; Fotis K. Konstantinidis; Symeon Symeonidis; Vasiliki Balaska; Dimitrios TsilisLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionData abstract:
The YogDATA dataset contains images from an industrial laboratory production line when it is functioned to quality yogurts. The case-study for the recognition of yogurt cups requires training of Mask R-CNN and YOLO v5.0 models with a set of corresponding images. Thus, it is important to collect the corresponding images to train and evaluate the class. Specifically, the YogDATA dataset includes the same labeled data for Mask R-CNN (coco format) and YOLO models. For the YOLO architecture, training and validation datsets include sets of images in jpg format and their annotations in txt file format. For the Mask R-CNN architecture, the annotation of the same sets of images are included in json file format (80% of images and annotations of each subset are in training set and 20% of images of each subset are in test set.)
Paper abstract:
The explosion of the digitisation of the traditional industrial processes and procedures is consolidating a positive impact on modern society by offering a critical contribution to its economic development. In particular, the dairy sector consists of various processes, which are very demanding and thorough. It is crucial to leverage modern automation tools and through-engineering solutions to increase their efficiency and continuously meet challenging standards. Towards this end, in this work, an intelligent algorithm based on machine vision and artificial intelligence, which identifies dairy products within production lines, is presented. Furthermore, in order to train and validate the model, the YogDATA dataset was created that includes yogurt cups within a production line. Specifically, we evaluate two deep learning models (Mask R-CNN and YOLO v5.0) to recognise and detect each yogurt cup in a production line, in order to automate the packaging processes of the products. According to our results, the performance precision of the two models is similar, estimating its at 99\%.IFeaLiD Example Datasets
- zenodo.org
zipUpdated Jul 22, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMartin Zurowietz; Martin Zurowietz (2024). IFeaLiD Example Datasets [Dataset]. http://doi.org/10.5281/zenodo.3741485zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.3741485Dataset updatedJul 22, 2024AuthorsMartin Zurowietz; Martin ZurowietzLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionExample datasets of the Interactive Feature Localization in Deep neural networks (IFeaLiD) tool.
Cityscapes
These datasets are based on the image
bielefeld_000000_007186_leftImg8bit.pngof the Cityscapes dataset. The datasets can be explored online in IFeaLiD:- conv2_x (
bielefeld_000000_007186_leftImg8bit.png.C1.npz.8.zip) - conv3_x (
bielefeld_000000_007186_leftImg8bit.png.C2.npz.8.zip) - conv4_x (
bielefeld_000000_007186_leftImg8bit.png.C3.npz.8.zip)
COCO
These datasets are based on the image
000000015746.jpgof the COCO dataset. The datasets can be explored online in IFeaLiD:- conv2_x (
000000015746.jpg.C1.npz.8.zip) - conv3_x (
000000015746.jpg.C2.npz.8.zip) - conv4_x (
000000015746.jpg.C3.npz.8.zip)
DIV2K
These datasets are based on the image
0804.pngof the DIV2K dataset. The datasets can be explored online in IFeaLiD:DOTA
These datasets are based on the image
P0034.pngof the DOTA dataset. The datasets can be explored online in IFeaLiD:- N
coco_mcgill's temporary collection: coco
- neurovault.org
niftiUpdated Feb 15, 2021+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2021). coco_mcgill's temporary collection: coco [Dataset]. http://identifiers.org/neurovault.image:441996niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:441996Dataset updatedFeb 15, 2021LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescription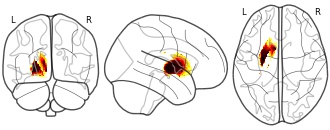
Collection description
None
Subject species
homo sapiens
Modality
Structural MRI
Cognitive paradigm (task)
None / Other
Map type
R
Fayl:Female coco de mer seed.jpg
- wikimedia.az-az.nina.az
Updated Jul 23, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCitewww.wikimedia.az-az.nina.az (2025). Fayl:Female coco de mer seed.jpg [Dataset]. https://www.wikimedia.az-az.nina.az/Fayl:Female_coco_de_mer_seed.jpg.htmlDataset updatedJul 23, 2025LicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionFayl Faylın tarixçəsi Faylın istifadəsi Faylın qlobal istifadəsi MetaməlumatlarSınaq göstərişi ölçüsü 543 599 piksel Dig
Udacity Self Driving Car Object Detection Dataset - fixed-large
- public.roboflow.com
zipUpdated Mar 24, 2025+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteRoboflow (2025). Udacity Self Driving Car Object Detection Dataset - fixed-large [Dataset]. https://public.roboflow.com/object-detection/self-driving-car/2zipAvailable download formatsDataset updatedMar 24, 2025Dataset authored and provided byRoboflowLicenseMIT Licensehttps://opensource.org/licenses/MIT
License information was derived automaticallyVariables measuredBounding Boxes of obstaclesDescriptionOverview
The original Udacity Self Driving Car Dataset is missing labels for thousands of pedestrians, bikers, cars, and traffic lights. This will result in poor model performance. When used in the context of self driving cars, this could even lead to human fatalities.
We re-labeled the dataset to correct errors and omissions. We have provided convenient downloads in many formats including VOC XML, COCO JSON, Tensorflow Object Detection TFRecords, and more.
Some examples of labels missing from the original dataset:
https://i.imgur.com/A5J3qSt.jpg" alt="Examples of Missing Labels">
Stats
The dataset contains 97,942 labels across 11 classes and 15,000 images. There are 1,720 null examples (images with no labels).
All images are 1920x1200 (download size ~3.1 GB). We have also provided a version downsampled to 512x512 (download size ~580 MB) that is suitable for most common machine learning models (including YOLO v3, Mask R-CNN, SSD, and mobilenet).
Annotations have been hand-checked for accuracy by Roboflow.
https://i.imgur.com/bOFkueI.pnghttps://" alt="Class Balance">
Annotation Distribution:
https://i.imgur.com/NwcrQKK.png" alt="Annotation Heatmap">
Use Cases
Udacity is building an open source self driving car! You might also try using this dataset to do person-detection and tracking.
Using this Dataset
Our updates to the dataset are released under the MIT License (the same license as the original annotations and images).
Note: the dataset contains many duplicated bounding boxes for the same subject which we have not corrected. You will probably want to filter them by taking the IOU for classes that are 100% overlapping or it could affect your model performance (expecially in stoplight detection which seems to suffer from an especially severe case of duplicated bounding boxes).
About Roboflow
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Developers reduce 50% of their boilerplate code when using Roboflow's workflow, save training time, and increase model reproducibility. :fa-spacer:

- h
CropCOCO
- huggingface.co
Updated Apr 10, 2025+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteVisual Recognition Group FEE CTU in Prague (2025). CropCOCO [Dataset]. https://huggingface.co/datasets/vrg-prague/CropCOCODataset updatedApr 10, 2025Dataset authored and provided byVisual Recognition Group FEE CTU in PragueLicensehttps://choosealicense.com/licenses/gpl-3.0/https://choosealicense.com/licenses/gpl-3.0/
DescriptionCropCOCO Dataset
CropCOCO is a validation-only dataset of COCO val 2017 images cropped such that some keypoints annotations are outside of the image. It can be used for keypoint detection, out-of-image keypoint detection and localization, person detection and amodal person detection.
📦 Dataset DetailsTotal images: 4,114 Annotations: COCO-style (bounding boxes, human keypoints, both in and out-of-image)Resolution: Varies Format: JSON annotations + JPG images… See the full description on the dataset page: https://huggingface.co/datasets/vrg-prague/CropCOCO.
ActiveHuman Part 2
- zenodo.org
- data.niaid.nih.gov
Updated Apr 24, 2025+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteCharalampos Georgiadis; Charalampos Georgiadis (2025). ActiveHuman Part 2 [Dataset]. http://doi.org/10.5281/zenodo.8361114Unique identifierhttps://doi.org/10.5281/zenodo.8361114Dataset updatedApr 24, 2025AuthorsCharalampos Georgiadis; Charalampos GeorgiadisLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis is Part 2/2 of the ActiveHuman dataset! Part 1 can be found here.
Dataset Description
ActiveHuman was generated using Unity's Perception package.
It consists of 175428 RGB images and their semantic segmentation counterparts taken at different environments, lighting conditions, camera distances and angles. In total, the dataset contains images for 8 environments, 33 humans, 4 lighting conditions, 7 camera distances (1m-4m) and 36 camera angles (0-360 at 10-degree intervals).
The dataset does not include images at every single combination of available camera distances and angles, since for some values the camera would collide with another object or go outside the confines of an environment. As a result, some combinations of camera distances and angles do not exist in the dataset.
Alongside each image, 2D Bounding Box, 3D Bounding Box and Keypoint ground truth annotations are also generated via the use of Labelers and are stored as a JSON-based dataset. These Labelers are scripts that are responsible for capturing ground truth annotations for each captured image or frame. Keypoint annotations follow the COCO format defined by the COCO keypoint annotation template offered in the perception package.
Folder configuration
The dataset consists of 3 folders:
- JSON Data: Contains all the generated JSON files.
- RGB Images: Contains the generated RGB images.
- Semantic Segmentation Images: Contains the generated semantic segmentation images.
Essential Terminology
- Annotation: Recorded data describing a single capture.
- Capture: One completed rendering process of a Unity sensor which stored the rendered result to data files (e.g. PNG, JPG, etc.).
- Ego: Object or person on which a collection of sensors is attached to (e.g., if a drone has a camera attached to it, the drone would be the ego and the camera would be the sensor).
- Ego coordinate system: Coordinates with respect to the ego.
- Global coordinate system: Coordinates with respect to the global origin in Unity.
- Sensor: Device that captures the dataset (in this instance the sensor is a camera).
- Sensor coordinate system: Coordinates with respect to the sensor.
- Sequence: Time-ordered series of captures. This is very useful for video capture where the time-order relationship of two captures is vital.
- UIID: Universal Unique Identifier. It is a unique hexadecimal identifier that can represent an individual instance of a capture, ego, sensor, annotation, labeled object or keypoint, or keypoint template.
Dataset Data
The dataset includes 4 types of JSON annotation files files:
- annotation_definitions.json: Contains annotation definitions for all of the active Labelers of the simulation stored in an array. Each entry consists of a collection of key-value pairs which describe a particular type of annotation and contain information about that specific annotation describing how its data should be mapped back to labels or objects in the scene. Each entry contains the following key-value pairs:
- id: Integer identifier of the annotation's definition.
- name: Annotation name (e.g., keypoints, bounding box, bounding box 3D, semantic segmentation).
- description: Description of the annotation's specifications.
- format: Format of the file containing the annotation specifications (e.g., json, PNG).
- spec: Format-specific specifications for the annotation values generated by each Labeler.
Most Labelers generate different annotation specifications in the spec key-value pair:
- BoundingBox2DLabeler/BoundingBox3DLabeler:
- label_id: Integer identifier of a label.
- label_name: String identifier of a label.
- KeypointLabeler:
- template_id: Keypoint template UUID.
- template_name: Name of the keypoint template.
- key_points: Array containing all the joints defined by the keypoint template. This array includes the key-value pairs:
- label: Joint label.
- index: Joint index.
- color: RGBA values of the keypoint.
- color_code: Hex color code of the keypoint
- skeleton: Array containing all the skeleton connections defined by the keypoint template. Each skeleton connection defines a connection between two different joints. This array includes the key-value pairs:
- label1: Label of the first joint.
- label2: Label of the second joint.
- joint1: Index of the first joint.
- joint2: Index of the second joint.
- color: RGBA values of the connection.
- color_code: Hex color code of the connection.
- SemanticSegmentationLabeler:
- label_name: String identifier of a label.
- pixel_value: RGBA values of the label.
- color_code: Hex color code of the label.
- captures_xyz.json: Each of these files contains an array of ground truth annotations generated by each active Labeler for each capture separately, as well as extra metadata that describe the state of each active sensor that is present in the scene. Each array entry in the contains the following key-value pairs:
- id: UUID of the capture.
- sequence_id: UUID of the sequence.
- step: Index of the capture within a sequence.
- timestamp: Timestamp (in ms) since the beginning of a sequence.
- sensor: Properties of the sensor. This entry contains a collection with the following key-value pairs:
- sensor_id: Sensor UUID.
- ego_id: Ego UUID.
- modality: Modality of the sensor (e.g., camera, radar).
- translation: 3D vector that describes the sensor's position (in meters) with respect to the global coordinate system.
- rotation: Quaternion variable that describes the sensor's orientation with respect to the ego coordinate system.
- camera_intrinsic: matrix containing (if it exists) the camera's intrinsic calibration.
- projection: Projection type used by the camera (e.g., orthographic, perspective).
- ego: Attributes of the ego. This entry contains a collection with the following key-value pairs:
- ego_id: Ego UUID.
- translation: 3D vector that describes the ego's position (in meters) with respect to the global coordinate system.
- rotation: Quaternion variable containing the ego's orientation.
- velocity: 3D vector containing the ego's velocity (in meters per second).
- acceleration: 3D vector containing the ego's acceleration (in ).
- format: Format of the file captured by the sensor (e.g., PNG, JPG).
- annotations: Key-value pair collections, one for each active Labeler. These key-value pairs are as follows:
- id: Annotation UUID .
- annotation_definition: Integer identifier of the annotation's definition.
- filename: Name of the file generated by the Labeler. This entry is only present for Labelers that generate an image.
- values: List of key-value pairs containing annotation data for the current Labeler.
Each Labeler generates different annotation specifications in the values key-value pair:
- BoundingBox2DLabeler:
- label_id: Integer identifier of a label.
- label_name: String identifier of a label.
- instance_id: UUID of one instance of an object. Each object with the same label that is visible on the same capture has different instance_id values.
- x: Position of the 2D bounding box on the X axis.
- y: Position of the 2D bounding box position on the Y axis.
- width: Width of the 2D bounding box.
- height: Height of the 2D bounding box.
- BoundingBox3DLabeler:
- label_id: Integer identifier of a label.
- label_name: String identifier of a label.
- instance_id: UUID of one instance of an object. Each object with the same label that is visible on the same capture has different instance_id values.
- translation: 3D vector containing the location of the center of the 3D bounding box with respect to the sensor coordinate system (in meters).
- size: 3D
- r
Tasmanian Orange Roughy Stereo Image Machine Learning Dataset
- researchdata.edu.au
- data.csiro.au
datadownloadUpdated Apr 7, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteCSIRO; Chris Jackett; Eric Orenstein; Kylie Maguire; Ben Scoulding; Christopher Jackett (2025). Tasmanian Orange Roughy Stereo Image Machine Learning Dataset [Dataset]. http://doi.org/10.25919/A90R-4962datadownloadAvailable download formatsUnique identifierhttps://doi.org/10.25919/A90R-4962Dataset updatedApr 7, 2025Dataset provided byCommonwealth Scientific and Industrial Research OrganisationAuthorsCSIRO; Chris Jackett; Eric Orenstein; Kylie Maguire; Ben Scoulding; Christopher JackettLicenseAttribution-NonCommercial-ShareAlike 4.0 (CC BY-NC-SA 4.0)https://creativecommons.org/licenses/by-nc-sa/4.0/
License information was derived automaticallyTime period coveredJul 11, 2019 - Jul 18, 2019Area coveredDescriptionThe Tasmanian Orange Roughy Stereo Image Machine Learning Dataset is a collection of annotated stereo image pairs collected by a net-attached Acoustic and Optical System (AOS) during orange roughy (Hoplostethus atlanticus) biomass surveys off the northeast coast of Tasmania, Australia in July 2019. The dataset consists of expertly annotated imagery from six AOS deployments (OP12, OP16, OP20, OP23, OP24, and OP32), representing a variety of conditions including different fish densities, benthic substrates, and altitudes above the seafloor. Each image was manually annotated with bounding boxes identifying orange roughy and other marine species. For all annotated images, paired stereo images from the opposite camera have been included where available to enable stereo vision analysis. This dataset was specifically developed to investigate the effectiveness of machine learning-based object detection techniques for automating fish detection under variable real-world conditions, providing valuable resources for advancing automated image processing in fisheries science. Lineage: Data were obtained onboard the 32 m Fishing Vessel Saxon Onward during an orange roughy acoustic biomass survey off the northeast coast of Tasmania in July 2019. Stereo image pairs were collected using a net-attached Acoustic and Optical System (AOS), which is a self-contained autonomous system with multi-frequency and optical capabilities mounted on the headline of a standard commercial orange roughy demersal trawl. Images were acquired by a pair of Prosilica GX3300 Gigabyte Ethernet cameras with Zeiss F2.8 lenses (25 mm focal length), separated by 90 cm and angled inward at 7° to provide 100% overlap at a 5 m range. Illumination was provided by two synchronised quantum trio strobes. Stereo pairs were recorded at 1 Hz in JPG format with a resolution of 3296 x 2472 pixels and a 24-bit depth.
Human experts manually annotated images from the six deployments using both the CVAT annotation tool (producing COCO format annotations) and LabelImg tool (producing XML format annotations). Only port camera views were annotated for all deployments. Annotations included bounding boxes for "orange roughy" and "orange roughy edge" (for partially visible fish), as well as other marine species (brittle star, coral, eel, miscellaneous fish, etc.). Prior to annotation, under-exposed images were enhanced based on altitude above the seafloor using a Dark Channel Prior (DCP) approach, and images taken above 10 m altitude were discarded due to poor visibility.
For all annotated images, the paired stereo images (from the opposite camera) have been included where available to enable stereo vision applications. The dataset represents varying conditions of fish density (1-59 fish per image), substrate types (light vs. dark), and altitudes (2.0-10.0 m above seafloor), making it particularly valuable for training and evaluating object detection models under variable real-world conditions.
The final standardised COCO dataset contains 1051 annotated port-side images, 849 paired images (without annotations), and 14414 total annotations across 17 categories. The dataset's category distribution includes orange roughy (9887), orange roughy edge (2928), mollusc (453), cnidaria (359), misc fish (337), sea anemone (136), sea star (105), sea feather (100), sea urchin (45), coral (22), eel (15), oreo (10), brittle star (8), whiptail (4), chimera (2), siphonophore (2), and shark (1).
- R
Cellphone Dataset
- universe.roboflow.com
zipUpdated Aug 9, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteWorkspace (2022). Cellphone Dataset [Dataset]. https://universe.roboflow.com/workspace-f5gtr/cellphone-bz5u9/dataset/1zipAvailable download formatsDataset updatedAug 9, 2022Dataset authored and provided byWorkspaceLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyVariables measuredPhones Bounding BoxesDescriptionThis represents a quick alternative as a subset of the 2017 coco dataset. With the choice of only using the cell phone class, annotation file and number of images. It contains the following directory tree:
- data/
- images/
- .jpg
- labels/
- train.json
- val.json
- images/
- Z
Data from: RafanoSet: Dataset of manually and automatically annotated...
- data.niaid.nih.gov
- zenodo.org
Updated Jan 14, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteRana, Shubham (2024). RafanoSet: Dataset of manually and automatically annotated Raphanus Raphanistrum weed images for object detection and segmentation [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_10510692Dataset updatedJan 14, 2024Dataset provided byCrimaldi, Mariano
Gerbino, Salvatore
Rana, ShubhamLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis dataset is a collection of manually and automatically annotated multispectral Images over Raphanus Raphanistrum infestations among Wheat crops.The images are categorized in two directories namely 'Manual' and 'Auotmated'. The sub-directory 'Manual' consists of manually acquired 85 images in .PNG format and annotations in COCO segmentation format titled region_data.json. Whereas, the sub-directory 'Automated' consists of 80 automatically annotated images in .JPG format and 80 annotation files in .XML Pascal VOC format.
The scientific framework of image acquisition and annotations are explained in the Data in Brief paper. This is just a prerequisite to the data article.
Roles:
The image acquisition was performed by Mariano Crimaldi, a researcher, on behalf of Department of Agriculture and the hosting institution University of Naples Federico II, Italy.Shubham Rana has been the curator and analyst for the data under the supervision of his PhD supervisor Prof. Salvatore Gerbino. They are affiliated with Department of Engineering, University of Campania 'Luigi Vanvitelli'. We are also in the process of articulating a data-in-brief article associated with this repository
Domenico Barretta, Department of Engineering has been associated in consulting and brainstorming role particularly with data and annotation management and litmus testing of the datasets.
HaGRID - HAnd Gesture Recognition Image Dataset
- kaggle.com
Updated Oct 21, 2022+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteAlexander Kapitanov (2022). HaGRID - HAnd Gesture Recognition Image Dataset [Dataset]. https://www.kaggle.com/datasets/kapitanov/hagrid/codeCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedOct 21, 2022AuthorsAlexander KapitanovLicenseAttribution-ShareAlike 4.0 (CC BY-SA 4.0)https://creativecommons.org/licenses/by-sa/4.0/
License information was derived automaticallyDescriptionhttps://github.com/hukenovs/hagrid/blob/master/images/hagrid.jpg?raw=true" alt="">
We introduce a large image dataset HaGRID (HAnd Gesture Recognition Image Dataset) for hand gesture recognition (HGR) systems. You can use it for image classification or image detection tasks. Proposed dataset allows to build HGR systems, which can be used in video conferencing services (Zoom, Skype, Discord, Jazz etc.), home automation systems, the automotive sector, etc.
HaGRID size is 716GB and dataset contains 552,992 FullHD (1920 × 1080) RGB images divided into 18 classes of gestures. Also, some images have
no_gestureclass if there is a second free hand in the frame. This extra class contains 123,589 samples. The data were split into training 92%, and testing 8% sets by subject user-id, with 509,323 images for train and 43,669 images for test.https://github.com/hukenovs/hagrid/raw/master/images/gestures.jpg" alt="">
The dataset contains 34,730 unique persons and at least this number of unique scenes. The subjects are people from 18 to 65 years old. The dataset was collected mainly indoors with considerable variation in lighting, including artificial and natural light. Besides, the dataset includes images taken in extreme conditions such as facing and backing to a window. Also, the subjects had to show gestures at a distance of 0.5 to 4 meters from the camera.
Annotations
The annotations consist of bounding boxes of hands with gesture labels in COCO format
[top left X position, top left Y position, width, height]. Also, annotations have 21landmarksin format[x,y]relative image coordinates, markups ofleading hands(leftofrightfor gesture hand) andleading_confas confidence forleading_handannotation. We provideuser_idfield that will allow you to split the train / val dataset yourself.json "0534147c-4548-4ab4-9a8c-f297b43e8ffb": { "bboxes": [ [0.38038597, 0.74085361, 0.08349486, 0.09142549], [0.67322755, 0.37933984, 0.06350809, 0.09187757] ], "landmarks"[ [ [ [0.39917091, 0.74502739], [0.42500172, 0.74984396], ... ], [0.70590734, 0.46012364], [0.69208878, 0.45407018], ... ], ], "labels": [ "no_gesture", "one" ], "leading_hand": "left", "leading_conf": 1.0, "user_id": "bb138d5db200f29385f..." }Downloads
We split the train dataset into 18 archives by gestures because of the large size of data. Download and unzip them from the following links:
Trainval
Gesture Size Gesture Size call 39.1 GB peace 38.6 GB dislike 38.7 GB peace_inverted 38.6 GB fist 38.0 GB rock 38.9 GB four 40.5 GB stop 38.3 GB like 38.3 GB stop_inverted 40.2 GB mute 39.5 GB three 39.4 GB ok 39.0 GB three2 38.5 GB one 39.9 GB two_up 41.2 GB palm 39.3 GB two_up_inverted 39.2 GB train_valannotations: ann_train_valTest
| Test...
- R
Fish Object Detection Dataset - 416x416
- public.roboflow.com
zipUpdated Feb 21, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteJacob Solawetz (2023). Fish Object Detection Dataset - 416x416 [Dataset]. https://public.roboflow.com/object-detection/fish/1zipAvailable download formatsDataset updatedFeb 21, 2023Dataset authored and provided byJacob SolawetzLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyVariables measuredBounding Boxes of fishDescriptionOverview
https://i.imgur.com/9hvxcRQ.jpg" alt="Image example">
This is an object detection dataset of ocean fish classified by their latin names.
https://i.imgur.com/ECPln18.jpg" alt="Image example">
Use Cases
This dataset can be used for the following purposes:
- Underwater object detection model
- Fish object detection model
- Train object detection model to recognize underwater species
- Prototype fish detection system
- Identifying fish with computer vision
- Free fish dataset
- Free fish identificaiton dataset
- Scuba diving object detection dataset
- Fish bounding boxes
- Fish species annotations
Enjoy! These images have been listed in the public domain.
Note: These images have been sourced from makeml.app/datasets/fish
- Z
Img2brain: Predicting the neural responses to visual stimuli of naturalistic...
- data.niaid.nih.gov
- zenodo.org
Updated Oct 16, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAyala-Ruano, Sebastian (2023). Img2brain: Predicting the neural responses to visual stimuli of naturalistic scenes using machine learning [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_7979729Dataset updatedOct 16, 2023Dataset authored and provided byAyala-Ruano, SebastianLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThe data for this project is part of the Natural Scenes Dataset (NSD), a massive dataset of 7T fMRI responses to images of natural scenes coming from the COCO dataset. The training dataset consists of brain responses measured at 10.000 brain locations (voxels) to 8857 images (in jpg format) for one subject. The 10.000 voxels are distributed around the visual pathway and may encode perceptual and semantic features in different proportions. The test dataset comprises 984 images (in jpg format), and the goal is to predict the brain responses to these images.
The zip file contains the following folders:
trainingIMG: contains the training images (8857) in jpg format. The numbering corresponds to the order of the rows in the brain response matrix.
testIMG: contains test images (984) in jpg format.
trainingfMRI: contains a npy file with the fMRI responses measured at 10000 brain locations (voxels) to the training images. The matrix has 8857 rows (one for each image) and 10000 columns (one for each voxel).
Tagged Anime Illustrations
- kaggle.com
Updated Jul 30, 2018ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMyles O'Neill (2018). Tagged Anime Illustrations [Dataset]. https://www.kaggle.com/mylesoneill/tagged-anime-illustrations/discussionCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedJul 30, 2018AuthorsMyles O'NeillDescriptionContext
This is a dataset of richly tagged and labeled artwork depicting characters from Japanese anime. The data comes from two image boards, danbooru and moeimouto. This data can be used in an variety of different interesting ways, from classification to generative modeling. Please note that while all of the images in this dataset have been tagged as SFW (non-explicit), the websites these are from do not ban explicit or pornographic images and mislabeled images are possibly still in the dataset.
Danbooru2017: A large-scale crowdsourced and tagged anime illustration dataset
The first set of data comes from the imageboard Danbooru. The entire corpus of Danbooru images was scraped from the site with permission and was collected into a dataset. The zip files included here have the full metadata for these images as well as a subset of 300,000 of the images in normalized 512px x 512px form. Full information about this dataset is available here:
https://www.gwern.net/Danbooru2017
From the article:
Deep learning for computer revision relies on large annotated datasets. Classification/categorization has benefited from the creation of ImageNet, which classifies 1m photos into 1000 categories. But classification/categorization is a coarse description of an image which limits application of classifiers, and there is no comparably large dataset of images with many tags or labels which would allow learning and detecting much richer information about images. Such a dataset would ideally be >1m images with at least 10 descriptive tags each which can be publicly distributed to all interested researchers, hobbyists, and organizations. There are currently no such public datasets, as ImageNet, Birds, Flowers, and MS COCO fall short either on image or tag count or restricted distribution. I suggest that the image -boorus be used. The image boorus are longstanding web databases which host large numbers of images which can be tagged or labeled with an arbitrary number of textual descriptions; they were developed for and are most popular among fans of anime, who provide detailed annotations.
The best known booru, with a focus on quality, is Danbooru. We create & provide a torrent which contains ~1.9tb of 2.94m images with 77.5m tag instances (of 333k defined tags, ~26.3/image) covering Danbooru from 24 May 2005 through 31 December 2017 (final ID: #2,973,532), providing the image files & a JSON export of the metadata. We also provide a smaller torrent of SFW images downscaled to 512x512px JPG (241GB; 2,232,462 images) for convenience.
Our hope is that a Danbooru2017 dataset can be used for rich large-scale classification/tagging & learned embeddings, test out the transferability of existing computer vision techniques (primarily developed using photographs) to illustration/anime-style images, provide an archival backup for the Danbooru community, feed back metadata improvements & corrections, and serve as a testbed for advanced techniques such as conditional image generation or style transfer.
Anime face character dataset
The second set of data included in this dataset is a little more manageable than the first, it includes a number of cropped illustrated faces from the now defunct site moeimouto. This dataset has been used in GAN work in the past. The data comes from:
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/
More information:
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/README.html
If you are interested in creating more face data (potentially from the Danbooru data), here is a helpful resource: https://github.com/nagadomi/lbpcascade_animeface
Other Data
If you are looking for something a little easier to crack into, check out this other great anime image booru dataset: https://www.kaggle.com/alamson/safebooru
- R
Pipeline Tracks Dataset
- universe.roboflow.com
zipUpdated Jan 15, 2025+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteUTP (2025). Pipeline Tracks Dataset [Dataset]. https://universe.roboflow.com/utp-jtbn5/pipeline-tracks/dataset/2zipAvailable download formatsDataset updatedJan 15, 2025Dataset authored and provided byUTPLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyVariables measuredPipeline Bounding BoxesDescriptionDescription: The Pipeline Tracks dataset is a curated collection comprising 2000 images, each focusing on a singular class - "pipe," specifically designed for pipe detection tasks.
Dataset Overview: - Images: 2553 - Class: Pipe
Use Case: The primary objective of this dataset is to serve as a valuable resource for training and evaluating machine learning models specialized in pipe detection within images.
Key Features: - Diversity: The dataset encompasses a diverse range of images, capturing pipes in various environmental conditions and settings. - Annotations: Images are annotated to facilitate model training, with precise labeling of pipe locations.
Dataset Structure: - Images/ - Image001.jpg - Image002.jpg - ... - Annotations/ - Image001.xml - Image002.xml - ...
How to Use: 1. Training: Utilize the dataset for training machine learning models, particularly those focused on detecting pipes in images. 2. Evaluation: Assess the performance of your models by testing them on the provided dataset.
Acknowledgments: The Pipeline Tracks dataset is made available by Ibrahim Aromoye, from Universiti Teknologi PETRONAS UTP, Malaysia, contributing to the advancement of object detection algorithms in the field of pipeline tracking.
Citation: If you use this dataset in your work, please cite it as follows:
Aromoye, Ibrahim Akinjobi. (2023). Pipeline Tracks Dataset. [https://universe.roboflow.com/utp-jtbn5/pipeline-tracks]Thank you for choosing the Pipeline Tracks dataset for your pipeline detection tasks. Happy coding!
FacebookTwittercoco2017
Image-text pairs from MS COCO2017.
Data origin
Data originates from cocodataset.org While coco-karpathy uses a dense format (with several sentences and sendids per row), coco-karpathy-long uses a long format with one sentence (aka caption) and sendid per row. coco-karpathy-long uses the first five sentences and therefore is five times as long as coco-karpathy. phiyodr/coco2017: One row corresponds one image with several sentences. phiyodr/coco2017-long: One row… See the full description on the dataset page: https://huggingface.co/datasets/phiyodr/coco2017.