NIfTI data files
- zenodo.org
- data.niaid.nih.gov
zipUpdated Jun 14, 2021 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCiteDavid Atkinson; David Atkinson (2021). NIfTI data files [Dataset]. http://doi.org/10.5281/zenodo.4940072zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.4940072Dataset updatedJun 14, 2021AuthorsDavid Atkinson; David AtkinsonLicense
EmailClick to copy linkLink copiedCiteDavid Atkinson; David Atkinson (2021). NIfTI data files [Dataset]. http://doi.org/10.5281/zenodo.4940072zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.4940072Dataset updatedJun 14, 2021AuthorsDavid Atkinson; David AtkinsonLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionNIfTI files to support the SIRF Exercises regarding Geometry.
Data from static phantoms in MRI and a PET/MR phantom - see readme file.
NIfTI-MRS Example Data
- zenodo.org
application/gzipUpdated Jul 10, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteWilliam T Clarke; William T Clarke (2021). NIfTI-MRS Example Data [Dataset]. http://doi.org/10.5281/zenodo.5085449application/gzipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.5085449Dataset updatedJul 10, 2021AuthorsWilliam T Clarke; William T ClarkeLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionExample data accompanying the data format specification for the NIfTI-MRS file format. NIfTI-MRS is a NIfTI derived format for storing magnetic resonance spectroscopy (MRS) and spectroscopic imaging (MRSI) data.
Example data is generated from code at the NIfTI-MRS GitHub repository.
Each file is named example_{n}.nii.gz and corresponds to the following list:
- Manually converted SVS - Water suppressed STEAM
- spec2nii converted SVS - Water suppressed STEAM
- spec2nii converted edited SVS - MEGA-PRESS
- Manually converted 31P FID-MRSI (CSI sequence)
- spec2nii converted sLASER-localised 1H MRSIs
- j-difference editing example (MEGA-PRESS)
- Variable echo time: full representation
- Variable echo time: short representation
- Multiple dynamic parameters "Fingerprinting"
- FSL-MRS processed MEGA-PRESS spectrum
Brats2020 Nifti format for DeepMedic
- kaggle.com
zipUpdated May 21, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDarkStell (2024). Brats2020 Nifti format for DeepMedic [Dataset]. https://www.kaggle.com/datasets/darksteeldragon/brats2020-nifti-format-for-deepmediczip(4468643987 bytes)Available download formatsDataset updatedMay 21, 2024AuthorsDarkStellLicensehttps://creativecommons.org/publicdomain/zero/1.0/https://creativecommons.org/publicdomain/zero/1.0/
DescriptionOverview: This dataset consists of brain tumor images from the BraTS2020 challenge, formatted in Nifti (.nii) files, specifically prepared for use with the DeepMedic framework. It includes both training and validation sets. This is my first dataset publication will update it and finetune, please feel free to ask and help me on what i need to edit
Content:
Training Data: Contains multimodal MRI scans (T1, T1Gd, T2, FLAIR) with corresponding ground truth segmentations. Validation Data: Includes multimodal MRI scans without ground truth segmentations for model validation. Metadata: Information about each scan and its respective patient.Use Case: Ideal for training and evaluating deep learning models for brain tumor segmentation using the DeepMedic framework.
License: Public Domain (CC0)
Size: 4.48 GB
Usage: This dataset can be used for developing and testing machine learning algorithms for medical image segmentation, particularly in the context of brain tumor analysis.
Citations: Please cite the BraTS2020 challenge and the authors of the dataset in any publications or presentations.
4D Nifti files for seed-based correlations
- figshare.com
application/gzipUpdated Dec 29, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteVincent van de Ven (2024). 4D Nifti files for seed-based correlations [Dataset]. http://doi.org/10.6084/m9.figshare.28057481.v1application/gzipAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.28057481.v1Dataset updatedDec 29, 2024AuthorsVincent van de VenLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionExperiment information: Transcranial alternating current stimulation was delivered during 3T fMRI using concentric circular electrodes over area P4 in stimulation periods that each included attention task and resting-state blocks. MR images were preprocessed, normalized and denoised using the CONN toolbox for Matlab (https://web.conn-toolbox.org/) and analysed using seed-based correlations.File information: This repository contains gzipped 4D-Nifti files of seed-based correlations as calculated using the Matlab CONN toolbox. Each filename refers to SBC_Subj.nii.gz. Each4D Nifti file contains 11 volumes that refer to the 11 experiment conditions:Volume 1 = null; Volume 2 = rest 10 Hz; Volume 3 = task 10 Hz; Volume 4 = rest 20 Hz; Volume 5 = task 20 Hz; Volume 6 = rest 40 Hz; Volume 7 = task 40 Hz; Volume 8 = rest 5 Hz; Volume 9 = task 5 Hz; Volume 10 = rest No Stimulation; Volume 11 = task No Stimulation.Seed correlation values are Fisher Z-normalized (for more information, see the CONN toolbox or the associated manuscript).
spleen nifti file
- kaggle.com
zipUpdated Mar 10, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAshraf Alsinglawi (2025). spleen nifti file [Dataset]. https://www.kaggle.com/datasets/ashrafalsinglawi/spleen-nifti-filezip(12882908 bytes)Available download formatsDataset updatedMar 10, 2025AuthorsAshraf AlsinglawiDescriptionAbdominal cross-section as NIFTI volume showing spleen. Note: NIFTI files store all their pixel dimensions in a single place - pixdim field.
- Z
HCP-YA Tractography Atlas (NIFTI Files)
- data.niaid.nih.gov
- zenodo.org
Updated Mar 1, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteFang-Cheng Yeh (2022). HCP-YA Tractography Atlas (NIFTI Files) [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_3627771Dataset updatedMar 1, 2022Dataset provided byUniversity of PittsburghAuthorsFang-Cheng YehLicenseAttribution-ShareAlike 4.0 (CC BY-SA 4.0)https://creativecommons.org/licenses/by-sa/4.0/
License information was derived automaticallyDescriptionYeh, F. C., Panesar, S., Fernandes, D., Meola, A., Yoshino, M., Fernandez-Miranda, J. C., ... & Verstynen, T. (2018). Population-averaged atlas of the macroscale human structural connectome and its network topology. NeuroImage, 178, 57-68.
- Z
Training Dataset for HNTSMRG 2024 Challenge
- data.niaid.nih.gov
Updated Jun 21, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteWahid, Kareem; Dede, Cem; Naser, Mohamed; Fuller, Clifton (2024). Training Dataset for HNTSMRG 2024 Challenge [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_11199558Dataset updatedJun 21, 2024Dataset provided byThe University of Texas MD Anderson Cancer CenterAuthorsWahid, Kareem; Dede, Cem; Naser, Mohamed; Fuller, CliftonLicenseAttribution-NonCommercial 4.0 (CC BY-NC 4.0)https://creativecommons.org/licenses/by-nc/4.0/
License information was derived automaticallyDescriptionTraining Dataset for HNTSMRG 2024 Challenge
Overview
This repository houses the publicly available training dataset for the Head and Neck Tumor Segmentation for MR-Guided Applications (HNTSMRG) 2024 Challenge.
Patient cohorts correspond to patients with histologically proven head and neck cancer who underwent radiotherapy (RT) at The University of Texas MD Anderson Cancer Center. The cancer types are predominately oropharyngeal cancer or cancer of unknown primary. Images include a pre-RT T2w MRI scan (1-3 weeks before start of RT) and a mid-RT T2w MRI scan (2-4 weeks intra-RT) for each patient. Segmentation masks of primary gross tumor volumes (abbreviated GTVp) and involved metastatic lymph nodes (abbreviated GTVn) are provided for each image (derived from multi-observer STAPLE consensus).
HNTSMRG 2024 is split into 2 tasks:
Task 1: Segmentation of tumor volumes (GTVp and GTVn) on pre-RT MRI.
Task 2: Segmentation of tumor volumes (GTVp and GTVn) on mid-RT MRI.
The same patient cases will be used for the training and test sets of both tasks of this challenge. Therefore, we are releasing a single training dataset that can be used to construct solutions for either segmentation task. The test data provided (via Docker containers), however, will be different for the two tasks. Please consult the challenge website for more details.
Data Details
DICOM files (images and structure files) have been converted to NIfTI format (.nii.gz) for ease of use by participants via DICOMRTTool v. 1.0.
Images are a mix of fat-suppressed and non-fat-suppressed MRI sequences. Pre-RT and mid-RT image pairs for a given patient are consistently either fat-suppressed or non-fat-suppressed.
Though some sequences may appear to be contrast enhancing, no exogenous contrast is used.
All images have been manually cropped from the top of the clavicles to the bottom of the nasal septum (~ oropharynx region to shoulders), allowing for more consistent image field of views and removal of identifiable facial structures.
The mask files have one of three possible values: background = 0, GTVp = 1, GTVn = 2 (in the case of multiple lymph nodes, they are concatenated into one single label). This labeling convention is similar to the 2022 HECKTOR Challenge.
150 unique patients are included in this dataset. Anonymized patient numeric identifiers are utilized.
The entire training dataset is ~15 GB.
Dataset Folder/File Structure
The dataset is uploaded as a ZIP archive. Please unzip before use. NIfTI files conform to the following standardized nomenclature: ID_timepoint_image/mask.nii.gz. For mid-RT files, a "registered" suffix (ID_timepoint_image/mask_registered.nii.gz) indicates the image or mask has been registered to the mid-RT image space (see more details in Additional Notes below).
The data is provided with the following folder hierarchy:
Top-level folder (named "HNTSMRG24_train")
Patient-level folder (anonymized patient ID, example: "2")
Pre-radiotherapy data folder ("preRT")
Original pre-RT T2w MRI volume (example: "2_preRT_T2.nii.gz").
Original pre-RT tumor segmentation mask (example: "2_preRT_mask.nii.gz").
Mid-radiotherapy data folder ("midRT")
Original mid-RT T2w MRI volume (example: "2_midRT_T2.nii.gz").
Original mid-RT tumor segmentation mask (example: "2_midRT_mask.nii.gz").
Registered pre-RT T2w MRI volume (example: "2_preRT_T2_registered.nii.gz").
Registered pre-RT tumor segmentation mask (example: "2_preRT_mask_registered.nii.gz").
Note: Cases will exhibit variable presentation of ground truth mask structures. For example, a case could have only a GTVp label present, only a GTVn label present, both GTVp and GTVn labels present, or a completely empty mask (i.e., complete tumor response at mid-RT). The following case IDs have empty masks at mid-RT (indicating a complete response): 21, 25, 29, 42. These empty masks are not errors. There will similarly be some cases in the test set for Task 2 that have empty masks.
Details Relevant for Algorithm Building
The goal of Task 1 is to generate a pre-RT tumor segmentation mask (e.g., "2_preRT_mask.nii.gz" is the relevant label). During blind testing for Task 1, only the pre-RT MRI (e.g., "2_preRT_T2.nii.gz") will be provided to the participants algorithms.
The goal of Task 2 is to generate a mid-RT segmentation mask (e.g., "2_midRT_mask.nii.gz" is the relevant label). During blind testing for Task 2, the mid-RT MRI (e.g., "2_midRT_T2.nii.gz"), original pre-RT MRI (e.g., "2_preRT_T2.nii.gz"), original pre-RT tumor segmentation mask (e.g., "2_preRT_mask.nii.gz"), registered pre-RT MRI (e.g., "2_preRT_T2_registered.nii.gz"), and registered pre-RT tumor segmentation mask (e.g., "2_preRT_mask_registered.nii.gz") will be provided to the participants algorithms.
When building models, the resolution of the generated prediction masks should be the same as the corresponding MRI for the given task. In other words, the generated masks should be in the correct pixel spacing and origin with respect to the original reference frame (i.e., pre-RT image for Task 1, mid-RT image for Task 2). More details on the submission of models will be located on the challenge website.
Additional Notes
General notes.
NIfTI format images and segmentations may be easily visualized in any NIfTI viewing software such as 3D Slicer.
Test data will not be made public until the completion of the challenge. The complete training and test data will be published together (along with all original multi-observer annotations and relevant clinical data) at a later date via The Cancer Imaging Archive. Expected date ~ Spring 2025.
Task 1 related notes.
When training their algorithms for Task 1, participants can choose to use only pre-RT data or add in mid-RT data as well. Initially, our plan was to limit participants to utilizing only pre-RT data for training their algorithms in Task 1. However, upon reflection, we recognized that in a practical setting, individuals aiming to develop auto-segmentation algorithms could theoretically train models using any accessible data at their disposal. Based on current literature, we actually don't know what the best solution would be! Would the incorporation of mid-RT data for training a pre-RT segmentation model actually be helpful, or would it merely introduce harmful noise? The answer remains unclear. Therefore, we leave this choice to the participants.
Remember, though, during testing, you will ONLY have the pre-RT image as an input to your model (naturally, since Task 1 is a pre-RT segmentation task and you won't know what mid-RT data for a patient will look like).
Task 2 related notes.
In addition to the mid-RT MRI and segmentation mask, we have also provided a registered pre-RT MRI and the corresponding registered pre-RT segmentation mask for each patient. We offer this data for participants who opt not to integrate any image registration techniques into their algorithms for Task 2 but still wish to use the two images as a joint input to their model. Moreover, in a real-world adaptive RT context, such registered scans are typically readily accessible. Naturally, participants are also free to incorporate their own image registration processes into their pipelines if they wish (or ignore the pre-RT images/masks altogether).
Registrations were generated using SimpleITK, where the mid-RT image serves as the fixed image and the pre-RT image serves as the moving image. Specifically, we utilized the following steps: 1. Apply a centered transformation, 2. Apply a rigid transformation, 3. Apply a deformable transformation with Elastix using a preset parameter map (Parameter map 23 in the Elastix Zoo). This particular deformable transformation was selected as it is open-source and was benchmarked in a previous similar application (https://doi.org/10.1002/mp.16128). For cases where excessive warping was noted during deformable registration (a small minority of cases), only the rigid transformation was applied.
Contact
We have set up a general email address that you can message to notify all organizers at: hntsmrg2024@gmail.com. Additional specific organizer contacts:
Kareem A. Wahid, PhD (kawahid@mdanderson.org)
Cem Dede, MD (cdede@mdanderson.org)
Mohamed A. Naser, PhD (manaser@mdanderson.org)
2D high-resolution synthetic MR images of Alzheimer's patients and healthy...
- zenodo.org
- data.niaid.nih.gov
application/gzip, csvUpdated Dec 13, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMatteo Lai; Matteo Lai; Chiara Marzi; Chiara Marzi; Luca Citi; Luca Citi; Stefano Diciotti; Stefano Diciotti (2023). 2D high-resolution synthetic MR images of Alzheimer's patients and healthy subjects using PACGAN [Dataset]. http://doi.org/10.5281/zenodo.8276786application/gzip, csvAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.8276786Dataset updatedDec 13, 2023AuthorsMatteo Lai; Matteo Lai; Chiara Marzi; Chiara Marzi; Luca Citi; Luca Citi; Stefano Diciotti; Stefano DiciottiDescriptionThis dataset encompasses a NIfTI file containing a collection of 500 images, each capturing the central axial slice of a synthetic brain MRI.
Accompanying this file is a CSV dataset that serves as a repository for the corresponding labels linked to each image:
- Label 0: Healthy Controls (HC)
- Label 1: Alzheimer's Disease (AD)
Each image within this dataset has been generated by PACGAN (Progressive Auxiliary Classifier Generative Adversarial Network), a framework designed and implemented by the AI for Medicine Research Group at the University of Bologna.
PACGAN is a generative adversarial network trained to generate high-resolution images belonging to different classes. In our work, we trained this framework on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, which contains brain MRI images of AD patients and HC.
The implementation of the training algorithm can be found within our GitHub repository, with Docker containerization.
For further exploration, the pre-trained models are available within the Code Ocean capsule. These models can facilitate the generation of synthetic images for both classes and also aid in classifying new brain MRI images.
- m
resting-state fMRI data for Normal adults
- data.mendeley.com
Updated Feb 4, 2021+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteTie-Qiang Li (2021). resting-state fMRI data for Normal adults [Dataset]. http://doi.org/10.17632/pt9d2rdv46.1Unique identifierhttps://doi.org/10.17632/pt9d2rdv46.1Dataset updatedFeb 4, 2021AuthorsTie-Qiang LiLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionWhole brine resting-state fMRI data from 227 healthy adults between 18 and 78 years old acquired at a 3T clinical MRI scanner. The tar file contains 227 compressed nifti files. The 1st alphabet in the file names indicates the gender of the volunteers (f for female and m for male). The 2nd and 3rd digits indicate the age of volunteers. The remaining alphabets are randomized to encode individual subjects. The original images were reconstructed into dicom format and converted into nifti file format.
MUG500+(B) Standardized Nifti Augmented Data
- figshare.com
binUpdated Dec 22, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteDhiren Oswal; Yugal Khanter (2023). MUG500+(B) Standardized Nifti Augmented Data [Dataset]. http://doi.org/10.6084/m9.figshare.24872079.v1binAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.24872079.v1Dataset updatedDec 22, 2023AuthorsDhiren Oswal; Yugal KhanterLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionFollowing data is an extension of MUG500(B) DOI: 10.6084/m9.figshare.9616319If using this dataset, please cite 10.6084/m9.figshare.24872079The MUG500(B) set has a "nrrd" defective skull scan file, with its respective implants in "stl" format.Front these 29 pairs, 27 pairs had single defects and 2 pairs had double defects, hence, two implants for one particular file.This dataset includes the converted "Nifti" file(float32) formatted 29 pairs of craniotomy defective skulls, and its manually designed implants, with a pair of implants and skull being resampled to one common ROI. Each pair with double defects was simplified to different samples by combining the volumes of the defective skull with one implant at a time. hence total available samples are 31.This standardized resampled nifti data is augmented with affine registration to obtain 930 pairs(31*30).Following is the folder structure of the augmented data:-----Augmented_data└── 03to01└── 4 files└── 03to02└── 4 files................
- u
Registered histology, MRI, and manual annotations of over 300 brain regions...
- rdr.ucl.ac.uk
txtUpdated Oct 6, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteEugenio Iglesias Gonzalez; Adria Casamitjana; Alessia Atzeni; Benjamin Billot; David Thomas; Emily Blackburn; James Hughes; Juri Althonayan; Loic Peter; Matteo Mancini; Nellie Robinson; Peter Schmidt; Shauna Crampsie (2023). Registered histology, MRI, and manual annotations of over 300 brain regions in 5 human hemispheres (data from ERC Starting Grant 677697 "BUNGEE-TOOLS") [Dataset]. http://doi.org/10.5522/04/24243835.v1txtAvailable download formatsUnique identifierhttps://doi.org/10.5522/04/24243835.v1Dataset updatedOct 6, 2023Dataset provided byUniversity College LondonAuthorsEugenio Iglesias Gonzalez; Adria Casamitjana; Alessia Atzeni; Benjamin Billot; David Thomas; Emily Blackburn; James Hughes; Juri Althonayan; Loic Peter; Matteo Mancini; Nellie Robinson; Peter Schmidt; Shauna CrampsieLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionSummary:
This repository includes data related to the ERC Starting Grant project 677697: "Building Next-Generation Computational Tools for High Resolution Neuroimaging Studies" (BUNGEE-TOOLS). It includes: (a) Dense histological sections from five human hemispheres with manual delineations of >300 brain regions; (b) Corresponding ex vivo MRI scans; (c) Dissection photographs; (d) A spatially aligned version of the dataset; (e) A probabilistic atlas built from the hemispheres; and (f) Code to apply the atlas to automated segmentation of in vivo MRI scans.
More detailed description on what this dataset includes:
Data files and Python code for Bayesian segmentation of human brain MRI based on a next-generation, high-resolution histological atlas: "Next-Generation histological atlas for high-resolution segmentation of human brain MRI" A Casamitjana et al., in preparation. This repository contains a set of zip files, each corresponding to one directory. Once decompressed, each directory has a readme.txt file explaining its contents. The list of zip files / compressed directories is:
3dAtlas.zip: nifti files with summary imaging volumes of the probabilistic atlas.
BlockFacePhotoBlocks.zip: nifti files with the blackface photographs acquired during tissue sectioning, reconstructed into 3D volumes (in RGB).
Histology.zip: jpg files with the LFB and H&E stained sections.
HistologySegmentations.zip: 2D nifti files with the segmentations of the histological sections.
MRI.zip: ex vivo T2-weighted MRI scans and corresponding FreeSurfer processing files
SegmentationCode.zip: contains the the Python code and data files that we used to segment brain MRI scans and obtain the results presented in the article (for reproducibility purposes). Note that it requires an installation of FreeSurfer. Also, note that the code is also maintained in FreeSurfer (but may not produce exactly the same results): https://surfer.nmr.mgh.harvard.edu/fswiki/HistoAtlasSegmentation
WholeHemispherePhotos.zip: photographs of the specimens prior to dissection
WholeSlicePhotos.zip: photographs of the tissue slabs prior to blocking.
We also note that the registered images for the five cases can be found in GitHub: https://github.com/UCL/BrainAtlas-P41-16 https://github.com/UCL/BrainAtlas-P57-16 https://github.com/UCL/BrainAtlas-P58-16 https://github.com/UCL/BrainAtlas-P85-18 https://github.com/UCL/BrainAtlas-EX9-19
These registered images can be interactively explored with the following web interface: https://github-pages.ucl.ac.uk/BrainAtlas/#/atlas Data from: Multilevel atlas comparisons reveal divergent evolution of the...
- zenodo.org
zipUpdated Sep 16, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteClément M. Garin; Clément M. Garin (2023). Multilevel atlas comparisons reveal divergent evolution of the primate brain [Dataset]. http://doi.org/10.5281/zenodo.8349978zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.8349978Dataset updatedSep 16, 2023AuthorsClément M. Garin; Clément M. GarinLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionNifti files of 20 mammalian atlases modified into a Common Multilevel Segmentation.
(See Figure 1 in Multilevel atlas comparisons reveal divergent evolution of the primate brain; https://www.pnas.org/doi/full/10.1073/pnas.2202491119#sec-3)
These nifti files are based on the brain atlases from 18 mammalian species, that were published between the years 2013 and 2021 (see list).
The Python script to re-segment the "original" atlases into the modified version (that is shared here) is also available:
see Modify_atlases.py
Each species folder contains 5 nifti files: 1 for each level of segmentation and 1 for the brain segmentation.
The other txt files are the volumetric output extracted using AFNI on each nifti file.
Please read the Readme.txt file to credit and cite accordingly all the authors.
pyAFQ Stanford HARDI tractography and mapping, updated
- figshare.com
binUpdated Aug 3, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteJohn Kruper; Ariel Rokem (2023). pyAFQ Stanford HARDI tractography and mapping, updated [Dataset]. http://doi.org/10.6084/m9.figshare.23848884.v1binAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.23848884.v1Dataset updatedAug 3, 2023AuthorsJohn Kruper; Ariel RokemLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis tractography and registration mapping was created from the data that is in this PURL on the Stanford Digital Repository: https://searchworks.stanford.edu/view/yx282xq2090.The data were processed using the pyAFQ software (https://github.com/yeatmanlab/pyAFQ) and Dipy, to create tensor-based tracts. These were down-sampled by a factor of 1000, and stored in the trk file. The data were also registered to the MNI T2 template, using the SyN algorithm (Avants et al. 2008), implemented in Dipy. Both forward and backward transformation images were saved and are stored the nifti files.
- D
A triple-network organization for the mouse brain
- data.ru.nl
18_380_v1Updated Oct 8, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteRoël Vrooman; Joanes Grandjean (2021). A triple-network organization for the mouse brain [Dataset]. http://doi.org/10.34973/raa0-5z2918_380_v1(81671624830 bytes)Available download formatsUnique identifierhttps://doi.org/10.34973/raa0-5z29Dataset updatedOct 8, 2021Dataset provided byRadboud UniversityAuthorsRoël Vrooman; Joanes GrandjeanLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis dataset contains the preprocessed data for "A triple-network organization for the mouse brain" by Mandino, Vrooman, Foo, Yeow et al. Folder structure: CAP/CAP_roi #regions of interest used for CAP analysis CAP/CSD #preprocessed NIFTI files for chronic social defeat model and control mice CAP/awake #preprocessed NIFTI files for awake mouse dataset CAP/awake_motion #motion vectors for awake mouse dataset insula_git #Long term copy of the code in https://gitlab.socsci.ru.nl/preclinical-neuroimaging/insula optoDR/ #preprocessed optoDR dataset https://openneuro.org/datasets/ds001541 optoINS/ #preprocessed optoINS dataset https://openneuro.org/datasets/ds003464
- S
Age- and enthinity-specific brain templates and growth charts for children...
- scidb.cn
Updated Dec 10, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteHao-Ming Dong; F. Xavier Castellanos; Ning Yang; Zhe Zhang; Quan Zhou; Ye He; Lei Zhang; Ting Xu; Avram J. Holmes; B.T. Thomas Yeo; Feiyan Chen; Bin Wang; Christian Beckmann; Tonya White; Olaf Sporns; Jiang Qiu; Tingyong Feng; Antao Chen; Xun Liu; Xu Chen; Xuchu Weng; Michael P. Milham; Xi-Nian Zuo (2020). Age- and enthinity-specific brain templates and growth charts for children and adolescents at school age [Dataset]. http://doi.org/10.11922/sciencedb.00362CroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Unique identifierhttps://doi.org/10.11922/sciencedb.00362Dataset updatedDec 10, 2020Dataset provided byScience Data BankAuthorsHao-Ming Dong; F. Xavier Castellanos; Ning Yang; Zhe Zhang; Quan Zhou; Ye He; Lei Zhang; Ting Xu; Avram J. Holmes; B.T. Thomas Yeo; Feiyan Chen; Bin Wang; Christian Beckmann; Tonya White; Olaf Sporns; Jiang Qiu; Tingyong Feng; Antao Chen; Xun Liu; Xu Chen; Xuchu Weng; Michael P. Milham; Xi-Nian ZuoLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionDescription: Brain growth charts and age-normed brain templates are essential resources for researchers to eventually contribute to the care of individuals with atypical developmental trajectories. The present work generates age-normed brain templates for children and adolescents at one-year intervals and the corresponding growth charts to investigate the influences of age and ethnicity using a common pediatric neuroimaging protocol. Two accelerated longitudinal cohorts with the identical experimental design were implemented in the United States and China. Anatomical magnetic resonance imaging (MRI) of typically developing school-age children (TDC) was obtained up to three times at nominal intervals of 1.25 years. The protocol generated and compared population- and age-specific brain templates and growth charts, respectively. A total of 674 Chinese pediatric MRI scans were obtained from 457 Chinese TDC and 190 American pediatric MRI scans were obtained from 133 American TDC.Population- and age-specific brain templates were used to quantify warp cost, the differences between individual brains and brain templates. Volumetric growth charts for labeled brain network areas were generated. Shape analyses of cost functions supported the necessity of age-specific and ethnicity-matched brain templates, which was confirmed by growth chart analyses. These analyses revealed volumetric growth differences between the two ethnicities primarily in lateral frontal and parietal areas, regions which are most variable across individuals in regard to their structure and function. Age- and ethnicity-specific brain templates facilitate establishing unbiased pediatric brain growth charts, indicating the necessity of the brain charts and brain templates generated in tandem. These templates and growth charts as well as related codes have been made freely available to the public for open neuroscience
Usage: The age-specific head brain templates can be used for pediatric neuroimaging studies to provide a standard reference on head brain spaces. Sample codes for such uses can be found on Github(https://github.com/zuoxinian/CCS/tree/master/H3/GrowthCharts). The growth charts on various school-age children and adolescents can provide a normal growth standard on the brain development across school age, together with the normative modeling methods, they offer an analytic way of implementing individualized or personalized pediatrics. All the templates and growth charts are downloadable as NIFTI files. For a given NIFTI file in the dataset, IPCAS indicates the Chinese school age template,NKI named files indicate American template.Users can find the age-specific template in the name of (IPCAS/NKI)_age(X)_brain_template.nii.gz and the different tissue template are also provided by this dataset in the name of (IPCAS/NKI)_age(X)_brain_pve(_0/_1/_2/seg) in which 0 indicates CSF, 1 indicates gray matter, 2 indicates white matter, and seg indicates hard segmentatin.
The Phantom of Bern: repeated scans of two volunteers with eight different...
- openneuro.org
Updated Apr 26, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteM. Rebsamen; D. Romascano; M. Capiglioni; R. Wiest; P. Radojewski; C. Rummel (2023). The Phantom of Bern: repeated scans of two volunteers with eight different combinations of MR sequence parameters [Dataset]. http://doi.org/10.18112/openneuro.ds004560.v1.0.0Unique identifierhttps://doi.org/10.18112/openneuro.ds004560.v1.0.0Dataset updatedApr 26, 2023AuthorsM. Rebsamen; D. Romascano; M. Capiglioni; R. Wiest; P. Radojewski; C. RummelLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyArea coveredBernDescriptionThe Phantom of Bern: repeated scans of two volunteers with eight different combinations of MR sequence parameters
The Phantom of Bern consists of eight same-session re-scans of T1-weighted MRI with different combinations of sequence parameters, acquired on two healthy subjects. The subjects have agreed in writing to the publication of these data, including the original anonymized DICOM files and waving the requirement of defacing. Usage is permitted under the terms of the data usage agreement stated below.
CONTENT
The BIDS directory is organized as follows:
└── PhantomOfBern/ ├─ code/ │ ├─ derivatives/ │ ├─ dldirect_v1-0-0/ │ │ ├─ results/ # Folder with flattened subject/session inputs and outputs of DL+DiReCT │ │ └─ stats2table/ # Folder with tables summarizing all DL+DiReCT outputs │ ├─ freesurfer_v6-0-0/ │ │ ├─ results/ # Folder with flattened subject/session inputs and outputs of freesurfer │ │ └─ stats2table/ # Folder with tables summarizing all freesurfer outputs │ └─ siena_v2-6/ │ ├─ SIENA_results.csv # Siena's main output │ └─ ... # Flattened subject/session inputs and outputs of SIENA │ ├─ sourcedata/ │ ├─ POBHC0001/ │ │ └─ 17473A/ │ │ └─ ... # Anonymized DICOM folders │ └─ POBHC0002/ │ └─ 14610A/ │ └─ ... # Anonymized DICOM folders │ ├─ sub-<label>/ │ └─ ses-<label>/ │ └─ anat/ # Folder with scan's json and nifti files ├─ ...ACKNOWLEDGEMENT
The dataset can be cited as:
M. Rebsamen, D. Romascano, M. Capiglioni, R. Wiest, P. Radojewski, C. Rummel. The Phantom of Bern: repeated scans of two volunteers with eight different combinations of MR sequence parameters. OpenNeuro, 2023.If you use these data, please also cite the original paper:
M. Rebsamen, M. Capiglioni, R. Hoepner, A. Salmen, R. Wiest, P. Radojewski, C. Rummel. Growing importance of brain morphometry analysis in the clinical routine: The hidden impact of MR sequence parameters. Journal of Neuroradiology, 2023.DATA USE AGREEMENT
The Phantom of Bern is distributed under the following terms, to which you agree by downloading and/or using the dataset:
- Any intentional identification of a subject or disclosure of his or her confidential information violates the promise of confidentiality given to the providers of the information. Therefore, all users of the dataset agree:
To use these datasets solely for research and development or statistical purposes and not for investigation of specific subjects
To make no use of the identity of any subject discovered inadvertently, and to advise the providers of any such discovery (crummel@web.de)
When publicly presenting any results or algorithms that benefited from the use of the Phantom of Bern, you should acknowledge it, see above. Papers, book chapters, books, posters, oral presentations, and all other printed and digital presentations of results derived from the Phantom of Bern data should cite the publications listed above.
Redistribution of data (complete or in parts) in any manner without explicit inclusion of this data use agreement is prohibited.
Usage of the data for testing commercial tools is explicitly allowed. Usage for military purposes is prohibited.
The original collector and provider of the data (see acknowledgement) and the relevant funding agency bear no responsibility for use of the data or for interpretations or inferences based upon such uses.
FUNDING
This work was supported by the Swiss National Science Foundation under grant numbers 204593 (ScanOMetrics) and CRSII5_180365 (The Swiss-First Study).
- d
Data for: A principled approach to synthesize neuroimaging data for...
- musc.digitalcommonsdata.com
Updated Apr 26, 2021+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteKenneth Vaden (2021). Data for: A principled approach to synthesize neuroimaging data for replication and exploration [Dataset]. http://doi.org/10.17632/3w9662wjpr.1Unique identifierhttps://doi.org/10.17632/3w9662wjpr.1Dataset updatedApr 26, 2021AuthorsKenneth VadenLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThe synthetic predictor tables and fully synthetic neuroimaging data produced for the analysis of fully synthetic data in the current study are available as Research Data available from Mendeley Data. Ten fully synthetic datasets include synthetic gray matter images (nifti files) that were generated for analysis with simulated participant data (text files). An archive file predictor_tables.tar.gz contains ten fully synthetic predictor tables with information for 264 simulated subjects. Due to large file sizes, a separate archive was created for each set of synthetic gray matter image data: RBS001.tar.gz, …, RBS010.tar.gz. Regression analyses were performed for each synthetic dataset, then average statistic maps were made for each contrast, which were then smoothed (see accompanying paper for additional information).
The supplementary materials also include commented MATLAB and R code to implement the current neuroimaging data synthesis methods (SKexample.zip). The example data were selected from an earlier fMRI study (Kuchinsky et al., 2012) to demonstrate that the current approach can be used with other types of neuroimaging data. The example code can also be adapted to produce fully synthetic group-level datasets based on observed neuroimaging data from other sources. The zip archive includes a document with important information for performing the example analyses, and details that should be communicated with recipients of a synthetic neuroimaging dataset.
Kuchinsky, S.E., Vaden, K.I., Keren, N.I., Harris, K.C., Ahlstrom, J.B., Dubno, J.R., Eckert, M.A., 2012. Word intelligibility and age predict visual cortex activity during word listening. Cerebral Cortex 22, 1360–71. https://doi.org/10.1093/cercor/bhr211
BraTS 2021: Harmonized MGMT & Survival (n=457)
- kaggle.com
zipUpdated Dec 17, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCitenazzmullxdxd (2025). BraTS 2021: Harmonized MGMT & Survival (n=457) [Dataset]. https://www.kaggle.com/datasets/nazzmullxdxd/brats2021-harmonized-clinical-n457zip(4368262187 bytes)Available download formatsDataset updatedDec 17, 2025AuthorsnazzmullxdxdLicensehttps://creativecommons.org/publicdomain/zero/1.0/https://creativecommons.org/publicdomain/zero/1.0/
DescriptionFLAT STRUCTURE (.nii). Uncompressed NIfTI files to prevent Kaggle auto-decompression folders. 457 glioblastoma patients. Includes subject 00556 (valid MGMT, missing Survival).
Axis 0 Slices
- kaggle.com
zipUpdated Dec 12, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAileen Liu (2022). Axis 0 Slices [Dataset]. https://www.kaggle.com/datasets/aileenliu54/axis-0-sliceszip(864042301 bytes)Available download formatsDataset updatedDec 12, 2022AuthorsAileen LiuDescriptionprocessed data from 3d brain segmentation dataset. This dataset contains 2d npy arrays for slices in the 0th axis of the ground truth masks and original images of each subject in the original dataset. The files are in the format: {train, valid, test}/{cohort}{subid}slc{slc#}_{img, mask}.npy. The masks have been combined into one array of shape ((4,) + img.shape), where the mask[0] is the background (0 = brain, 1 = background), mask[1] is the csf mask, mask[2] is the gray matter mask, mask[3] is the white matter mask. The slices are taken every 16 pixels.
From original dataset description: "There are MRI T1 brain scans of 726 subjects in this dataset. This dataset is a combination of three datasets. In this dataset, you will find three folders: train, valid, and test. Each folder has two subfolders: image and mask. In the image folder, you will find the **NIFTI **files of MRI T1 brain scans and in the mask folder, you'll find three probability masks per scan. Raw image file names (inputs) are in this format: {train, valid, test}/image/{cohort}{subid}img.nii.gz And masks (ground truth) are: {train, valid, test}/mask/{cohort}{subid}probmask_{csf, graymatter, whitematter}.nii.gz The "subid" is subject ID and "cohort" is the abbreviation of cohort name which can be either "dlbs", "salad", or "ixi". Each mask (csf, graymatter, and whitematter) contains likelihood values for each voxel that belong to: csf: Cerebrospinal fluid graymatter: Gray matter whitematter: White matter Thus, the sum of values per voxel must be 1.0 if it belongs to brain regions; otherwise, the sum is zero. All raw images and masks are registered on the MNI152 atlas. Note: Please cite the original dataset providers: DLBS https://fcon_1000.projects.nitrc.org/indi/retro/dlbs.html IXI https://brain-development.org/ixi-dataset/ SALD http://fcon_1000.projects.nitrc.org/indi/retro/sald.html Special thanks to Dr. Jia Guo, and Vish Rao for organizing the dataset."
- N
Morphospace of white matter cognition: ambiguous.nii
- neurovault.org
niftiUpdated Jul 3, 2025+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2025). Morphospace of white matter cognition: ambiguous.nii [Dataset]. http://identifiers.org/neurovault.image:903154niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:903154Dataset updatedJul 3, 2025LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionfMRI data was projected into the white matter using the Functionnectome. The number of subjectes refers to the number of fMRI literature sources
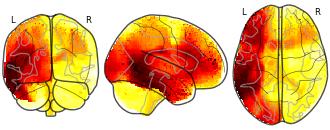
Collection description
Description: To characterise the organisation of cognitive processes in the brain's white matter, we created a morphospace following the procedure described in Pacella et al (2024). We used 506 meta-analytic association maps from Neurosynth (www.neurosynth.org) projected to the white matter, which are statistical representations of fMRI activation patterns linked to specific cognitive terms. Here, we upload the files to build this morphospace: - `Images/` – NIfTI files for 506 cognitive terms (from Neurosynth) projected to the white matter
Subject species
homo sapiens
Modality
fMRI-BOLD
Analysis level
meta-analysis
Cognitive paradigm (task)
Other evaluation task
Map type
Other
FacebookTwitterAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automatically
NIfTI files to support the SIRF Exercises regarding Geometry.
Data from static phantoms in MRI and a PET/MR phantom - see readme file.