- f
Data from: Facial Expression Image Dataset for Computer Vision Algorithms
- salford.figshare.com
Updated Apr 29, 2025 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCiteAli Alameer; Odunmolorun Osonuga (2025). Facial Expression Image Dataset for Computer Vision Algorithms [Dataset]. http://doi.org/10.17866/rd.salford.21220835.v2Unique identifierhttps://doi.org/10.17866/rd.salford.21220835.v2Dataset updatedApr 29, 2025Dataset provided byUniversity of SalfordAuthorsAli Alameer; Odunmolorun OsonugaLicense
EmailClick to copy linkLink copiedCiteAli Alameer; Odunmolorun Osonuga (2025). Facial Expression Image Dataset for Computer Vision Algorithms [Dataset]. http://doi.org/10.17866/rd.salford.21220835.v2Unique identifierhttps://doi.org/10.17866/rd.salford.21220835.v2Dataset updatedApr 29, 2025Dataset provided byUniversity of SalfordAuthorsAli Alameer; Odunmolorun OsonugaLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThe dataset for this project is characterised by photos of individual human emotion expression and these photos are taken with the help of both digital camera and a mobile phone camera from different angles, posture, background, light exposure, and distances. This task might look and sound very easy but there were some challenges encountered along the process which are reviewed below: 1) People constraint One of the major challenges faced during this project is getting people to participate in the image capturing process as school was on vacation, and other individuals gotten around the environment were not willing to let their images be captured for personal and security reasons even after explaining the notion behind the project which is mainly for academic research purposes. Due to this challenge, we resorted to capturing the images of the researcher and just a few other willing individuals. 2) Time constraint As with all deep learning projects, the more data available the more accuracy and less error the result will produce. At the initial stage of the project, it was agreed to have 10 emotional expression photos each of at least 50 persons and we can increase the number of photos for more accurate results but due to the constraint in time of this project an agreement was later made to just capture the researcher and a few other people that are willing and available. These photos were taken for just two types of human emotion expression that is, “happy” and “sad” faces due to time constraint too. To expand our work further on this project (as future works and recommendations), photos of other facial expression such as anger, contempt, disgust, fright, and surprise can be included if time permits. 3) The approved facial emotions capture. It was agreed to capture as many angles and posture of just two facial emotions for this project with at least 10 images emotional expression per individual, but due to time and people constraints few persons were captured with as many postures as possible for this project which is stated below: Ø Happy faces: 65 images Ø Sad faces: 62 images There are many other types of facial emotions and again to expand our project in the future, we can include all the other types of the facial emotions if time permits, and people are readily available. 4) Expand Further. This project can be improved furthermore with so many abilities, again due to the limitation of time given to this project, these improvements can be implemented later as future works. In simple words, this project is to detect/predict real-time human emotion which involves creating a model that can detect the percentage confidence of any happy or sad facial image. The higher the percentage confidence the more accurate the facial fed into the model. 5) Other Questions Can the model be reproducible? the supposed response to this question should be YES. If and only if the model will be fed with the proper data (images) such as images of other types of emotional expression.
- f
Facial Perception Data Post Stimulation/Sham Results
- figshare.com
txtUpdated Jun 1, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteTristan Bless; Nathaniel Goodman; Patrick Mulvany; Jessica Cramer; Fiza Singh; Jaime A. Pineda (2023). Facial Perception Data Post Stimulation/Sham Results [Dataset]. http://doi.org/10.6084/m9.figshare.7834526.v2txtAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.7834526.v2Dataset updatedJun 1, 2023Dataset provided byfigshareAuthorsTristan Bless; Nathaniel Goodman; Patrick Mulvany; Jessica Cramer; Fiza Singh; Jaime A. PinedaLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionAnimate/inanimate face recognition task was administered using the Presentation program (Neurobehavioral Systems). Face stimuli were obtained from Looser & Wheatley (2010) who morphed twenty inanimate faces with well-matched photographs of human faces using FantaMorph software (Version 3; Abrosoft Co., Beijing, China). The resulting image sets were the product of linear interpolation between the two (human/mannequin) original images. This kept the increments of physical change consistent across the morphing continuum, which consisted of 5 ‘human’ faces (1-5, containing 60-100% human aspects) and 5 ‘mannequin’ faces (7-11, containing 60-100% mannequin aspects) and a sixth, middle face that was considered a 50% human-50% mannequin version.This task consisted of the presentation of 9 blocks of faces presented on a different 15” laptop screen, placed at about eye level approximately 66 cm in front of participants. Each face stimulus block contained a sequence of 11 human-like faces morphed as previously described. This provided a total of 99 faces. When instructed to begin, participants saw a randomly selected face in the middle of the screen, (W: 10-12 cm; H: 11-15 cm) followed by a question as to whether the face was inanimate (1) or animate (2). Each trial lasted 3000ms (1000 ms face stimuli duration and 2000 ms response screen duration). Participants were instructed to relax and minimize movements since EEG was being recorded simultaneously.Presentation of faces was immediately followed by a question as to whether the face was inanimate (1) or animate (2). Reaction times (RTs) were collected for those responses. Outlier analysis of the data was performed in which RTs more than two standard deviations above or below the mean were removed. Participant responses were also analyzed by using polynomial regression fitting to compute the functions representing subjects’ responses. This was done by collecting and analyzing response data from individual subjects across the 9 face blocks (Cheetham & Jancke, 2013), each of which was shown to participants before and after stimulation. Each of the 9 face blocks contained 11 different morph images with a unique morph identifier, also known as a face continua. Response data for each face continua were aggregated and averaged, generating 9 functions displaying the response data prior to stimulation and 9 functions following stimulation. In pooling the 18 different polynomial curves, four cumulative functions were generated -- one for pre-STIM, post-STIM, pre-SHAM, and post-SHAM, thus allowing larger inferences on how participants responded to each morph image prior to and following the onset of stimulation to be drawn. Once the four cumulative functions were generated, the point of subjective equality (PSE) was calculated. This is the point at which a face was equally likely to be deemed animate or inanimate (following Looser & Wheatley, 2010). It was done by finding the polynomial function associated with the fitted curve and finding the x-coordinate corresponding to the point at which the function reached the 50% recognition point.
A fMRI dataset in response to large number of short natural dynamic facial...
- openneuro.org
Updated Oct 10, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCitePanpan Chen; Chi Zhang; Bao Li; Li Tong; Linyuan Wang; Shuxiao Ma; Long Cao; Ziya Yu; Bin Yan (2024). A fMRI dataset in response to large number of short natural dynamic facial expression videos [Dataset]. http://doi.org/10.18112/openneuro.ds005047.v1.0.4Unique identifierhttps://doi.org/10.18112/openneuro.ds005047.v1.0.4Dataset updatedOct 10, 2024AuthorsPanpan Chen; Chi Zhang; Bao Li; Li Tong; Linyuan Wang; Shuxiao Ma; Long Cao; Ziya Yu; Bin YanLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionSummary
Facial expression is among the most natural methods for human beings to convey their emotional information in daily life. Although the neural mechanism of facial expression has been extensively studied employing lab-controlled images and a small number of lab-controlled video stimuli, how the human brain processes natural facial expressions still needs to be investigated. To our knowledge, this type of data specifically on large number of natural facial expression videos is currently missing. We describe here the natural Facial Expressions Dataset (NFED), a fMRI dataset including responses to 1,320 short (3-second) natural facial expression video clips. These video clips is annotated with three types of labels: emotion, gender, and ethnicity, along with accompanying metadata. We validate that the dataset has good quality within and across participants and, notably, can capture temporal and spatial stimuli features. NFED provides researchers with fMRI data for understanding of the visual processing of large number of natural facial expression videos.
Data Records
The data, which were structured following the BIDS format53, were accessible at https://openneuro.org/datasets/ds00504754. The “sub-
Stimulus. Distinct folders store the stimuli for distinct fMRI experiments: "stimuli/face-video", "stimuli/floc", and "stimuli/prf" (Fig. 2b). The category labels and metadata corresponding to video stimuli are stored in the "videos-stimuli_category_metadata.tsv”. The “videos-stimuli_description.json” file describes category and metadata information of video stimuli(Fig. 2b).
Raw MRI data. Each participant's folder is comprised of 11 session folders: “sub-
Volume data from pre-processing. The pre-processed volume-based fMRI data were in the folder named “pre-processed_volume_data/sub-
Surface data from pre-processing. The pre-processed surface-based data were stored in a file named “volumetosurface/sub-
FreeSurfer recon-all. The results of reconstructing the cortical surface were saved as “recon-all-FreeSurfer/sub-
Surface-based GLM analysis data. We have conducted GLMsingle on the data of the main experiment. There is a file named “sub--
Validation. The code of technical validation was saved in the “derivatives/validation/code” folder. The results of technical validation were saved in the “derivatives/validation/results” folder (Fig. 2h). “README.md” describes the detailed information of code and results.
- o
Facial reactions to face representations in art dataset
- osf.io
Updated Jun 30, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAmel Achour-Benallegue (2021). Facial reactions to face representations in art dataset [Dataset]. http://doi.org/10.17605/OSF.IO/YK7HZUnique identifierhttps://doi.org/10.17605/OSF.IO/YK7HZDataset updatedJun 30, 2021Dataset provided byCenter For Open ScienceAuthorsAmel Achour-BenallegueDescriptionSupplementary materials for the submitted article: Facial reactions to face representations in art.
Gender Detection & Classification - Face Dataset
- kaggle.com
Updated Oct 31, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteTraining Data (2023). Gender Detection & Classification - Face Dataset [Dataset]. https://www.kaggle.com/datasets/trainingdatapro/gender-detection-and-classification-image-datasetCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedOct 31, 2023AuthorsTraining DataLicenseAttribution-NonCommercial-NoDerivs 4.0 (CC BY-NC-ND 4.0)https://creativecommons.org/licenses/by-nc-nd/4.0/
License information was derived automaticallyDescriptionGender Detection & Classification - face recognition dataset
The dataset is created on the basis of Face Mask Detection dataset
Dataset Description:
The dataset comprises a collection of photos of people, organized into folders labeled "women" and "men." Each folder contains a significant number of images to facilitate training and testing of gender detection algorithms or models.
The dataset contains a variety of images capturing female and male individuals from diverse backgrounds, age groups, and ethnicities.
https://www.googleapis.com/download/storage/v1/b/kaggle-user-content/o/inbox%2F12421376%2F1c4708f0b856f7889e3c0eea434fe8e2%2FFrame%2045%20(1).png?generation=1698764294000412&alt=media" alt="">
This labeled dataset can be utilized as training data for machine learning models, computer vision applications, and gender detection algorithms.
💴 For Commercial Usage: Full version of the dataset includes 376 000+ photos of people, leave a request on TrainingData to buy the dataset
Metadata for the full dataset:
- assignment_id - unique identifier of the media file
- worker_id - unique identifier of the person
- age - age of the person
- true_gender - gender of the person
- country - country of the person
- ethnicity - ethnicity of the person
- photo_1_extension, photo_2_extension, photo_3_extension, photo_4_extension - photo extensions in the dataset
- photo_1_resolution, photo_2_resolution, photo_3_extension, photo_4_resolution - photo resolution in the dataset
OTHER BIOMETRIC DATASETS:
- Anti Spoofing Real Dataset
- Antispoofing Replay Dataset
- Selfies, ID Images dataset (5591 sets of 15 files)
- Selfies and video dataset (4 052 sets)
- Dataset of bald people, 5000 images
💴 Buy the Dataset: This is just an example of the data. Leave a request on https://trainingdata.pro/datasets to learn about the price and buy the dataset
Content
The dataset is split into train and test folders, each folder includes: - folders women and men - folders with images of people with the corresponding gender, - .csv file - contains information about the images and people in the dataset
File with the extension .csv
- file: link to access the file,
- gender: gender of a person in the photo (woman/man),
- split: classification on train and test
TrainingData provides high-quality data annotation tailored to your needs
keywords: biometric system, biometric system attacks, biometric dataset, face recognition database, face recognition dataset, face detection dataset, facial analysis, gender detection, supervised learning dataset, gender classification dataset, gender recognition dataset
- N
BrainPedia: Henson face dataset: unfamiliar_faces_vs_baseline
- neurovault.org
niftiUpdated Oct 26, 2016+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2016). BrainPedia: Henson face dataset: unfamiliar_faces_vs_baseline [Dataset]. http://identifiers.org/neurovault.image:28112niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:28112Dataset updatedOct 26, 2016LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescription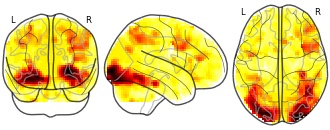
Collection description
We introduce a new method for detecting differences in the latency of blood oxygenation level-dependent (BOLD) responses to brief events within the context of the General Linear Model. Using a first-order Taylor approximation in terms of the temporal derivative of a canonical hemodynamic response function, statistical parametric maps of differential latencies were estimated via the ratio of derivative to canonical parameter estimates. This method was applied to two example datasets: comparison of words versus nonwords in a lexical decision task and initial versus repeated presentations of faces in a fame-judgment task. Tests across subjects revealed both magnitude and latency differences within several brain regions. This approach offers a computationally efficient means of detecting BOLD latency differences over the whole brain. Precise characterization of the hemodynamic latency and its interpretation in terms of underlying neural differences remain problematic, however.
Subject species
homo sapiens
Modality
fMRI-BOLD
Analysis level
single-subject
Map type
Z
- h
The face of illusory truth: Repetition of information elicits affective...
- heidata.uni-heidelberg.de
csv, txtUpdated Jan 17, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAnnika Stump; Annika Stump; Torsten Wüstenberg; Torsten Wüstenberg; Jeffrey N. Rouder; Jeffrey N. Rouder; Andreas Voss; Andreas Voss (2025). The face of illusory truth: Repetition of information elicits affective facial reactions predicting judgments of truth [Dataset] [Dataset]. http://doi.org/10.11588/DATA/2PKECXcsv(1085627), txt(819)Available download formatsUnique identifierhttps://doi.org/10.11588/DATA/2PKECXDataset updatedJan 17, 2025Dataset provided byheiDATAAuthorsAnnika Stump; Annika Stump; Torsten Wüstenberg; Torsten Wüstenberg; Jeffrey N. Rouder; Jeffrey N. Rouder; Andreas Voss; Andreas VossLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDataset funded byDeutsche Forschungsgemeinschaft (DFG)DescriptionPeople tend to judge repeated information as more likely being true compared to new information. A key explanation for this phenomenon, called the illusory truth effect, is that repeated information can be processed more fluently, causing it to appear more familiar and trustworthy. To consider the function of time in investigating its underlying cognitive and affective mechanisms, our design comprised two retention intervals. 75 participants rated the truth of new and repeated statements 10 minutes as well as 1 week after first exposure while spontaneous facial expressions were assessed via electromyography. Our data demonstrate that repetition results in specific facial reactions indicating increased positive affect, reduced mental effort, and increased familiarity (i.e., relaxations of musculus corrugator supercilii and frontalis), and subsequently increases the probability of judging information as true. The results moreover highlight the relevance of time: both repetition-induced truth effect and EMG activities decrease significantly after a longer interval.
Dataset for Familiar face detection in 180ms
- figshare.com
zipUpdated Jun 1, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMatteo Visconti di Oleggio Castello; M. Ida Gobbini (2023). Dataset for Familiar face detection in 180ms [Dataset]. http://doi.org/10.6084/m9.figshare.1489755.v1zipAvailable download formatsUnique identifierhttps://doi.org/10.6084/m9.figshare.1489755.v1Dataset updatedJun 1, 2023AuthorsMatteo Visconti di Oleggio Castello; M. Ida GobbiniLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionDataset containing reaction times to the simultaneous presentation of personally familiar faces, stranger faces, or objects.
- f
Table_1_East Asian Young and Older Adult Perceptions of Emotional Faces From...
- frontiersin.figshare.com
xlsxUpdated May 31, 2023+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteYu-Zhen Tu; Dong-Wei Lin; Atsunobu Suzuki; Joshua Oon Soo Goh (2023). Table_1_East Asian Young and Older Adult Perceptions of Emotional Faces From an Age- and Sex-Fair East Asian Facial Expression Database.XLSX [Dataset]. http://doi.org/10.3389/fpsyg.2018.02358.s003xlsxAvailable download formatsUnique identifierhttps://doi.org/10.3389/fpsyg.2018.02358.s003Dataset updatedMay 31, 2023Dataset provided byFrontiersAuthorsYu-Zhen Tu; Dong-Wei Lin; Atsunobu Suzuki; Joshua Oon Soo GohLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyArea coveredEast AsiaDescriptionThere is increasing interest in clarifying how different face emotion expressions are perceived by people from different cultures, of different ages and sex. However, scant availability of well-controlled emotional face stimuli from non-Western populations limit the evaluation of cultural differences in face emotion perception and how this might be modulated by age and sex differences. We present a database of East Asian face expression stimuli, enacted by young and older, male and female, Taiwanese using the Facial Action Coding System (FACS). Combined with a prior database, this present database consists of 90 identities with happy, sad, angry, fearful, disgusted, surprised and neutral expressions amounting to 628 photographs. Twenty young and 24 older East Asian raters scored the photographs for intensities of multiple-dimensions of emotions and induced affect. Multivariate analyses characterized the dimensionality of perceived emotions and quantified effects of age and sex. We also applied commercial software to extract computer-based metrics of emotions in photographs. Taiwanese raters perceived happy faces as one category, sad, angry, and disgusted expressions as one category, and fearful and surprised expressions as one category. Younger females were more sensitive to face emotions than younger males. Whereas, older males showed reduced face emotion sensitivity, older female sensitivity was similar or accentuated relative to young females. Commercial software dissociated six emotions according to the FACS demonstrating that defining visual features were present. Our findings show that East Asians perceive a different dimensionality of emotions than Western-based definitions in face recognition software, regardless of age and sex. Critically, stimuli with detailed cultural norms are indispensable in interpreting neural and behavioral responses involving human facial expression processing. To this end, we add to the tools, which are available upon request, for conducting such research.
- n
Data from: Two areas for familiar face recognition in the primate brain
- data.niaid.nih.gov
- search.dataone.org
- +2more
zipUpdated Jul 3, 2018ShareFacebookTwitterEmailClick to copy linkLink copiedCiteSofia M. Landi; Winrich A. Freiwald (2018). Two areas for familiar face recognition in the primate brain [Dataset]. http://doi.org/10.5061/dryad.10g45zipAvailable download formatsUnique identifierhttps://doi.org/10.5061/dryad.10g45Dataset updatedJul 3, 2018Dataset provided byRockefeller UniversityAuthorsSofia M. Landi; Winrich A. FreiwaldLicensehttps://spdx.org/licenses/CC0-1.0.htmlhttps://spdx.org/licenses/CC0-1.0.html
DescriptionFamiliarity alters face recognition: Familiar faces are recognized more accurately than unfamiliar ones and under difficult viewing conditions when unfamiliar face recognition fails. The neural basis for this fundamental difference remains unknown. Using whole-brain functional magnetic resonance imaging, we found that personally familiar faces engage the macaque face-processing network more than unfamiliar faces. Familiar faces also recruited two hitherto unknown face areas at anatomically conserved locations within the perirhinal cortex and the temporal pole. These two areas, but not the core face-processing network, responded to familiar faces emerging from a blur with a characteristic nonlinear surge, akin to the abruptness of familiar face recognition. In contrast, responses to unfamiliar faces and objects remained linear. Thus, two temporal lobe areas extend the core face-processing network into a familiar face-recognition system.
- m
Data from: From global-to-local? Uncovering the temporal dynamics of the...
- data.mendeley.com
Updated Sep 8, 2019ShareFacebookTwitterEmailClick to copy linkLink copiedCiteDaniel Fitousi (2019). From global-to-local? Uncovering the temporal dynamics of the composite face illusion using distributional analyses [Dataset]. http://doi.org/10.17632/w6pch45myr.1Unique identifierhttps://doi.org/10.17632/w6pch45myr.1Dataset updatedSep 8, 2019AuthorsDaniel FitousiLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThe data are the result of an experiment with composite faces. This is a standard composite face task in which a study and test composite faces are presented one after the other. The participant's task is to indicate whether the top half of the test and study faces are 'same' or 'different'. Both RTs and accuracy are measured.
- h
Data from: reactiongif
- huggingface.co
- opendatalab.com
Updated Apr 10, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteJulien Chaumond (2024). reactiongif [Dataset]. https://huggingface.co/datasets/julien-c/reactiongifCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedApr 10, 2024AuthorsJulien ChaumondLicensehttps://choosealicense.com/licenses/unknown/https://choosealicense.com/licenses/unknown/
DescriptionReactionGIF
From https://github.com/bshmueli/ReactionGIF
Excerpt from original repo readmeReactionGIF is a unique, first-of-its-kind dataset of 30K sarcastic tweets and their GIF reactions. To find out more about ReactionGIF, check out our ACL 2021 paper:
Shmueli, Ray and Ku, Happy Dance, Slow Clap: Using Reaction GIFs to Predict Induced Affect on Twitter
CitationIf you use our dataset, kindly cite the paper using the following BibTex entry:… See the full description on the dataset page: https://huggingface.co/datasets/julien-c/reactiongif.
- Z
Data from: BIRAFFE: Bio-Reactions and Faces for Emotion-based...
- data.niaid.nih.gov
- zenodo.org
Updated Jul 19, 2024ShareFacebookTwitterEmailClick to copy linkLink copiedCiteNalepa, Grzegorz J. (2024). BIRAFFE: Bio-Reactions and Faces for Emotion-based Personalization [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_3442143Dataset updatedJul 19, 2024Dataset provided byNalepa, Grzegorz J.
Kutt, Krzysztof
Bobek, SzymonLicenseAttribution-NonCommercial-NoDerivs 4.0 (CC BY-NC-ND 4.0)https://creativecommons.org/licenses/by-nc-nd/4.0/
License information was derived automaticallyDescriptionWe present BIRAFFE, a dataset consisting of electrocardiogram (ECG), galvanic skin reaction (GSR) and changes in facial expression signals recorded during affect elicitation by means of audio-visual stimuli (from IADS and IAPS databases) and our two proof-of-concept affective games ("Affective SpaceShooter 2" and "Fred Me Out 2"). All the signals were captured using portable and low-cost equipment: BITalino (r)evolution kit for ECG and GSR, and Creative Live! web camera for face photos (further analyzed by MS Face API).
Besides the signals, the dataset consists also of subjects' self-assessment of their affective state after each stimuli (with the use of two widgets: the first one with 5 emoticons and the second with valence and arousal dimensions) and "Big Five" personality traits assessment (using NEO-FFI inventory).
For detailed description see BIRAFFE-AfCAI2019-paper.pdf. For preview of the files before downloading the whole dataset see sample-SUB1107-[...] files.
All documents and papers that report on research that uses the BIRAFFE dataset should acknowledge this by citing the paper: Kutt, K., Drążyk, D., Jemioło, P., Bobek, S., Giżycka, B., Rodriguez-Fernandez, V., & Nalepa, G. J. (2020). "BIRAFFE: Bio-Reactions and Faces for Emotion-based Personalization". In G. J. Nalepa, J. M. Ferrandez, J. Palma, & V. Julian (Eds.), Proceedings of the 3rd Workshop on Affective Computing and Context Awareness in Ambient Intelligence (AfCAI 2019) (CEUR-WS Vol. 2609). http://ceur-ws.org/Vol-2609/
Our research related to the BIRAFFE dataset is summarized in: Kutt, K., Drążyk, D., Bobek, S., & Nalepa, G. J. (2021). "Personality-Based Affective Adaptation Methods for Intelligent Systems". Sensors, 21(1), 163. https://doi.org/10.3390/s21010163
- h
Python-React-Code-Dataset
- huggingface.co
Updated Feb 7, 2024+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteAmmar Khairi (2024). Python-React-Code-Dataset [Dataset]. https://huggingface.co/datasets/ammarnasr/Python-React-Code-DatasetCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedFeb 7, 2024AuthorsAmmar KhairiDescriptionammarnasr/Python-React-Code-Dataset dataset hosted on Hugging Face and contributed by the HF Datasets community
- Z
Adjudicating between face-coding models with individual-face fMRI responses:...
- data.niaid.nih.gov
- zenodo.org
Updated Jan 24, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteKriegeskorte, Nikolaus (2020). Adjudicating between face-coding models with individual-face fMRI responses: Data and analysis software [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_242666Dataset updatedJan 24, 2020Dataset provided byKriegeskorte, Nikolaus
Carlin, Johan DLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionComputational model fits to human neuroimaging data. Please see included readme.txt file.
- m
Data from: Face Mask Reduces Gaze-Cueing Effect
- data.mendeley.com
Updated Jul 8, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteZhonghua Hu (2023). Face Mask Reduces Gaze-Cueing Effect [Dataset]. http://doi.org/10.17632/zfd3s5hpzn.1Unique identifierhttps://doi.org/10.17632/zfd3s5hpzn.1Dataset updatedJul 8, 2023AuthorsZhonghua HuLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDescriptionThis data is for the article “ Face Mask Reduces Gaze-Cueing Effect”. This dataset contains the raw data and process data of reaction time and accuracy of Experiment 1 and 2.
AFFEC Multimodal Dataset
- zenodo.org
json, zipUpdated Mar 18, 2025ShareFacebookTwitterEmailClick to copy linkLink copiedCiteMeisam Jamshidi Seikavandi; Meisam Jamshidi Seikavandi; Laurits Dixen; Laurits Dixen; Paolo Burelli; Paolo Burelli (2025). AFFEC Multimodal Dataset [Dataset]. http://doi.org/10.5281/zenodo.14794876zip, jsonAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.14794876Dataset updatedMar 18, 2025AuthorsMeisam Jamshidi Seikavandi; Meisam Jamshidi Seikavandi; Laurits Dixen; Laurits Dixen; Paolo Burelli; Paolo BurelliLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyTime period coveredMay 1, 2024DescriptionDataset: AFFEC - Advancing Face-to-Face Emotion Communication Dataset
Overview
The AFFEC (Advancing Face-to-Face Emotion Communication) dataset is a multimodal dataset designed for emotion recognition research. It captures dynamic human interactions through electroencephalography (EEG), eye-tracking, galvanic skin response (GSR), facial movements, and self-annotations, enabling the study of felt and perceived emotions in real-world face-to-face interactions. The dataset comprises 84 simulated emotional dialogues, 72 participants, and over 5,000 trials, annotated with more than 20,000 emotion labels.
Dataset Structure
The dataset follows the Brain Imaging Data Structure (BIDS) format and consists of the following components:
Root Folder:
sub-*: Individual subject folders (e.g.,sub-aerj,sub-mdl,sub-xx2)dataset_description.json: General dataset metadataparticipants.jsonandparticipants.tsv: Participant demographics and attributestask-fer_events.json: Event annotations for the FER taskREADME.md: This documentation file
Subject Folders (
sub-):Each subject folder contains:
- Behavioral Data (
beh/): Physiological recordings (eye tracking, GSR, facial analysis, cursor tracking) in JSON and TSV formats. - EEG Data (
eeg/): EEG recordings in.edfand corresponding metadata in.json. - Event Files (
*.tsv): Trial event data for the emotion recognition task. - Channel Descriptions (
*_channels.tsv): EEG channel information.
Data Modalities and Channels
1. Eye Tracking Data
- Channels: 16 (fixation points, left/right eye gaze coordinates, gaze validity)
- Sampling Rate: 62 Hz
- Trials: 5632
- File Example:
sub-
2. Pupil Data
- Channels: 21 (pupil diameter, eye position, pupil validity flags)
- Sampling Rate: 149 Hz
- Trials: 5632
- File Example:
sub-
3. Cursor Tracking Data
- Channels: 4 (cursor X, cursor Y, cursor state)
- Sampling Rate: 62 Hz
- Trials: 5632
- File Example:
sub-
4. Face Analysis Data
- Channels: Over 200 (2D/3D facial landmarks, gaze detection, facial action units)
- Sampling Rate: 40 Hz
- Trials: 5680
- File Example:
sub-
5. Electrodermal Activity (EDA) and Physiological Sensors
- Channels: 40 (GSR, body temperature, accelerometer data)
- Sampling Rate: 50 Hz
- Trials: 5438
- File Example:
sub-
6. EEG Data
- Channels: 63 (EEG electrodes following the 10-20 placement scheme)
- Sampling Rate: 256 Hz
- Reference: Left earlobe
- Trials: 5632
- File Example:
sub-
7. Self-Annotations
- Trials: 5807
- Annotations Per Trial: 4
- Event Markers: Onset time, duration, trial type, emotion labels
- File Example:
task-fer_events.json
Experimental Setup
Participants engaged in a Facial Emotion Recognition (FER) task, where they watched emotionally expressive video stimuli while their physiological and behavioral responses were recorded. Participants provided self-reported ratings for both perceived and felt emotions, differentiating between the emotions they believed the video conveyed and their internal affective experience.
The dataset enables the study of individual differences in emotional perception and expression by incorporating Big Five personality trait assessments and demographic variables.
Usage Notes
- The dataset is formatted in ASCII/UTF-8 encoding.
- Each modality is stored in JSON, TSV, or EDF format as per BIDS standards.
- Researchers should cite this dataset appropriately in publications.
Applications
AFFEC is well-suited for research in:
- Affective Computing
- Human-Agent Interaction
- Emotion Recognition and Classification
- Multimodal Signal Processing
- Neuroscience and Cognitive Modeling
- Healthcare and Mental Health Monitoring
Acknowledgments
This dataset was collected with the support of brAIn lab, IT University of Copenhagen.
Special thanks to all participants and research staff involved in data collection.License
This dataset is shared under the Creative Commons CC0 License.
Contact
For questions or collaboration inquiries, please contact [brainlab-staff@o365team.itu.dk].
- R
Flash Mdp Face Detection Dataset
- universe.roboflow.com
zipUpdated Aug 4, 2023ShareFacebookTwitterEmailClick to copy linkLink copiedCiteflash mdp 2023 (2023). Flash Mdp Face Detection Dataset [Dataset]. https://universe.roboflow.com/flash-mdp-2023-euc2e/flash-mdp-face-detection/model/8zipAvailable download formatsDataset updatedAug 4, 2023Dataset authored and provided byflash mdp 2023LicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyVariables measuredFaces Bounding BoxesDescriptionHere are a few use cases for this project:
Security and Surveillance: The "FLASH MDP Face Detection" can be employed in security systems to identify individuals in public spaces or private buildings. This can help prevent unauthorized access and keep track of people's movement in monitored areas.
Driver Monitoring Systems: The model can be used in advanced driver assistance systems (ADAS) and autonomous vehicles to recognize and monitor drivers' faces to ensure attentiveness, detect drowsiness or distraction, and provide timely alerts to enhance road safety.
Social Media and Photo Management: The face detection model can be utilized in social media platforms and photo management applications to automatically recognize and tag faces, enabling users to effortlessly search for people, organize their images, and create personalized albums.
Retail and Marketing Analytics: The "FLASH MDP Face Detection" can be integrated into retail environments and digital signage systems to analyze customers' faces, helping businesses gather insights on demographics, emotional responses to products, and preferred store layouts, ultimately improving the customer experience.
Smart Access and Attendance Systems: The model can be implemented in workplaces, schools, and conferences, where facial recognition is used as a means of access control or attendance tracking. This would save time, streamline operations, and enhance security while maintaining user privacy.
- P
Data from: CARL Database Dataset
- paperswithcode.com
- opendatalab.com
Updated Feb 23, 2022ShareFacebookTwitterEmailClick to copy linkLink copiedCiteVirginia Espinosa-Duró; Marcos Faundez-Zanuy; Jiří Mekyska (2022). CARL Database Dataset [Dataset]. https://paperswithcode.com/dataset/carl-databaseDataset updatedFeb 23, 2022AuthorsVirginia Espinosa-Duró; Marcos Faundez-Zanuy; Jiří MekyskaDescriptionVisible and thermal images have been acquired using a thermographic camera TESTO 880-3, equipped with an uncooled detector with a spectral sensitivity range from 8 to 14 μm and provided with a germanium optical lens, and an approximate cost of 8.000 EUR. For the NIR a customized Logitech Quickcam messenger E2500 has been used, provided with a Silicon based CMOS image sensor with a sensibility to the overall visible spectrum and the half part of the NIR (until 1.000 nm approximately) with a cost of approx. 30 EUR. We have replaced the default optical filter of this camera by a couple of Kodak daylight filters for IR interspersed between optical and sensor. They both have similar spectrum responses and are coded as wratten filter 87 and 87C, respectively. In addition, we have used a special purpose printed circuit board (PCB) with a set of 16 infrared leds (IRED) with a range of emission from 820 to 1.000 nm in order to provide the required illumination.
The thermographic camera provides a resolution of 160×120 pixels for thermal images and 640×480 for visible images, while the webcam provides a still picture maximum resolution of 640×480 for near-infrared images and this has been the final resolution selected for our experiments.
A couple of halogen focus disposed 30 degrees away from the frontal direction and about 3 m away from the user, match the artificial light of the room. Note that all the tripods and structures have fixed markings on the ground.
- h
react-retrieval-datasets
- huggingface.co
Updated Jun 27, 2016ShareFacebookTwitterEmailClick to copy linkLink copiedCiteREACT (2016). react-retrieval-datasets [Dataset]. https://huggingface.co/datasets/react-vl/react-retrieval-datasetsCroissantCroissant is a format for machine-learning datasets. Learn more about this at mlcommons.org/croissant.Dataset updatedJun 27, 2016Dataset authored and provided byREACTDescriptionreact-vl/react-retrieval-datasets dataset hosted on Hugging Face and contributed by the HF Datasets community
FacebookTwitterAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automatically
The dataset for this project is characterised by photos of individual human emotion expression and these photos are taken with the help of both digital camera and a mobile phone camera from different angles, posture, background, light exposure, and distances. This task might look and sound very easy but there were some challenges encountered along the process which are reviewed below: 1) People constraint One of the major challenges faced during this project is getting people to participate in the image capturing process as school was on vacation, and other individuals gotten around the environment were not willing to let their images be captured for personal and security reasons even after explaining the notion behind the project which is mainly for academic research purposes. Due to this challenge, we resorted to capturing the images of the researcher and just a few other willing individuals. 2) Time constraint As with all deep learning projects, the more data available the more accuracy and less error the result will produce. At the initial stage of the project, it was agreed to have 10 emotional expression photos each of at least 50 persons and we can increase the number of photos for more accurate results but due to the constraint in time of this project an agreement was later made to just capture the researcher and a few other people that are willing and available. These photos were taken for just two types of human emotion expression that is, “happy” and “sad” faces due to time constraint too. To expand our work further on this project (as future works and recommendations), photos of other facial expression such as anger, contempt, disgust, fright, and surprise can be included if time permits. 3) The approved facial emotions capture. It was agreed to capture as many angles and posture of just two facial emotions for this project with at least 10 images emotional expression per individual, but due to time and people constraints few persons were captured with as many postures as possible for this project which is stated below: Ø Happy faces: 65 images Ø Sad faces: 62 images There are many other types of facial emotions and again to expand our project in the future, we can include all the other types of the facial emotions if time permits, and people are readily available. 4) Expand Further. This project can be improved furthermore with so many abilities, again due to the limitation of time given to this project, these improvements can be implemented later as future works. In simple words, this project is to detect/predict real-time human emotion which involves creating a model that can detect the percentage confidence of any happy or sad facial image. The higher the percentage confidence the more accurate the facial fed into the model. 5) Other Questions Can the model be reproducible? the supposed response to this question should be YES. If and only if the model will be fed with the proper data (images) such as images of other types of emotional expression.