- s
studyforrest_data_structural
- studyforrest.org
Updated Dec 18, 2020 Share
Share Facebook
Facebook Twitter
Twitter EmailClick to copy linkLink copiedCiteMichael Hanke (2020). studyforrest_data_structural [Dataset]. https://studyforrest.org/Dataset updatedDec 18, 2020AuthorsMichael HankeLicense
EmailClick to copy linkLink copiedCiteMichael Hanke (2020). studyforrest_data_structural [Dataset]. https://studyforrest.org/Dataset updatedDec 18, 2020AuthorsMichael HankeLicenseODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automaticallyDescriptionThis dataset contains T1 and T2 weighted MRI scans, susceptibility weighted images, and diffusion imaging scans. These data are suitable for analyses of brain structure. For more information about the project visit: http://studyforrest.org
- s
studyforrest_phase2
- studyforrest.org
Updated Dec 18, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAyan Sengupta; Michael Hanke; Jörg Stadler; Michael Hoffmann; Florian J. Baumgartner; Falko R. Kaule; Vittorio Iacovella; J. Swaroop Guntupalli; Daniel Kottke; Christian Häusler (2020). studyforrest_phase2 [Dataset]. https://studyforrest.org/Dataset updatedDec 18, 2020AuthorsAyan Sengupta; Michael Hanke; Jörg Stadler; Michael Hoffmann; Florian J. Baumgartner; Falko R. Kaule; Vittorio Iacovella; J. Swaroop Guntupalli; Daniel Kottke; Christian HäuslerLicenseODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automaticallyDescriptionExtension of the dataset published in Hanke et al. (2014; doi:10.1038/sdata.2014.3) with additional acquisitions for 15 of the original 20 particpants. These additions include: retinotopic mapping, a localizer paradigm for higher visual areas (FFA, EBA, PPA), and another 2h movie recording with 3T full-brain BOLD fMRI with simultaneous 1000 Hz eyetracking.
- s
studyforrest_multires7t
- studyforrest.org
Updated Dec 18, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAyan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael Hanke (2020). studyforrest_multires7t [Dataset]. https://studyforrest.org/Dataset updatedDec 18, 2020AuthorsAyan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael HankeLicenseODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automaticallyDescriptionExtension of the dataset published in Hanke et al. (2014; doi:10.1038/sdata.2014.3) with additional acquisitions for 6 of the original 20 participants (and one additional participant). Participants performed a central fixation task while being stimulated with oriented gratings. The experiment was repeated in four different sessions with 7T BOLD fMRI acquisition, each with a different scan resolution (0.8, 1.4, 2.0, and 3.0 mm).
studyforrest-data-multires7t: First public release
- zenodo.org
zipUpdated Jan 24, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAyan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael Hanke; Ayan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael Hanke (2020). studyforrest-data-multires7t: First public release [Dataset]. http://doi.org/10.5281/zenodo.46756zipAvailable download formatsUnique identifierhttps://doi.org/10.5281/zenodo.46756Dataset updatedJan 24, 2020AuthorsAyan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael Hanke; Ayan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael HankeLicenseODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automaticallyDescriptionstudyforrest.org: Multi-resolution 7T fMRI on visual orientation representation [BIDS]
Here we presentcempirical ultra high-field fMRI data recorded at four spatial resolutions (0.8 mm, 1.4 mm, 2 mm, and 3 mm isotropic voxel size) for orientation decoding in visual cortex — in order to test hypotheses on the strength and spatial scale of orientation discriminating signals. The entire dataset and the analysis codes presented in BIDS (Brain Imaging Data Structure).
studyforrest_movie_denoised
- openneuro.org
Updated Dec 3, 2019ShareFacebookTwitterEmailClick to copy linkLink copiedCiteXingyu Liu; Zonglei Zhen; Anmin Yang; Haohao Bai; Jia Liu (2019). studyforrest_movie_denoised [Dataset]. http://doi.org/10.18112/openneuro.ds001769.v1.3.0Unique identifierhttps://doi.org/10.18112/openneuro.ds001769.v1.3.0Dataset updatedDec 3, 2019AuthorsXingyu Liu; Zonglei Zhen; Anmin Yang; Haohao Bai; Jia LiuLicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionA manually denoised audio-visual movie watching fMRI dataset for the studyforrest project
Note: This dataset is compatible with the BIDS v1.3.0-dev as a standalone derivative dataset. Due to that the OpenNeuro.org does not support the BIDs v1.3.0 yet ('desc-
Source data
We here provide a denoised version of the studyforrest 3T movie-watching fMRI data. Specifically, the studyforrest 3T movie-watching fMRI dataset was hosted as ‘ses-movie’ under OpenNeuro ds000113 (https://openneuro.org/datasets/ds000113). Historically, the studyforrest 3T movie-watching fMRI data was hosted as ds000113d on OpenfMRI (https://legacy.openfmri.org/dataset/ds000113d/). It shall be noted that ‘ses-movie’ under OpenNeuro ds000113 and OpenfMRI ds000113d are the same data, just different in names.
For more information about the studyforrest project, please refer to the data papers of the studyforrest project and visit http://studyforrest.org.
Hanke, M. et al. A high-resolution 7-Tesla fMRI dataset from complex natural stimulation with an audio movie. Sci. Data 1, sdata20143 (2014).
Hanke, M. et al. A studyforrest extension, simultaneous fMRI and eye gaze recordings during prolonged natural stimulation. Sci. Data 3, 160092 (2016).Pipeline description
A four-step procedure was used to denoise the movie-watching fMRI dataset from the studyforrest project, producing a denoised version of the data.
- The data were preprocessed using FEAT in FSL v6.00 (https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FEAT) including motion correction, slice timing correction, brain extraction, high-pass temporal filtering (200s cutoff) and with or without spatial smoothing (i.e., FWHM= 5 mm or FWHM=0 mm).
- ICA was performed with MELODIC v3.15 (https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/MELODIC).
- IC classification was manually performed using melview (https://git.fmrib.ox.ac.uk/fsl/melview).
- Artifact removal was performed using fsl_regfilt in FSL’s MELODIC v3.15.
All code for data denoising and technical validation can be found at https://github.com/xingyu-liu/studyforrest_denoise.
Dataset content overview
After the four-step denoising procedure, 4 kinds of data were produced for each run of each participant.
- the denoised fMRI data
./sub-xx/ses-movie/func/sub-xx_ses-movie_task-movie-run-x_space-T1w_desc-{sm5,unsm}Denoised_bold.nii.gz - spatial maps of decomposed ICs
./sub-xx/ses-movie/func/sub-xx_ses-movie_task-movie-run-x_space-T1w_desc-{sm5,unsm}MELODIC_components.nii.gz - timeseries of decomposed ICs
./sub-xx/ses-movie/func/sub-xx_ses-movie_task-movie-run-x_space-T1w_desc-{sm5,unsm}MELODIC_mixing.tsv - Labels of decomposed ICs
./sub-xx/ses-movie/func/sub-xx_ses-movie_task-movie-run-x_space-T1w_desc-{sm5,unsm}MELODIC_decomposition.json
- N
High-resolution 7-Tesla fMRI data on the perception of musical genres – an...
- neurovault.org
niftiUpdated Jun 30, 2018ShareFacebookTwitterEmailClick to copy linkLink copiedCite(2018). High-resolution 7-Tesla fMRI data on the perception of musical genres – an extension to the studyforrest dataset: 4-way genre classification accuracy [Dataset]. http://identifiers.org/neurovault.image:10040niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:10040Dataset updatedJun 30, 2018LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescriptionSupport vector machine searchlight accuracy map. Radius of the spherical ROIs was two voxels (plus center). ROIs were spaced by two voxels. Accuracy scores mapped onto a voxels are the mean accuracy of all ROI analysis a voxel was included into.
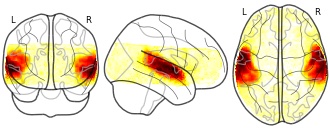
Collection description
The twenty participants were repeatedly stimulated with a total of 25 music clips, with and without speech content, from five different genres using a slow event-related paradigm. The data release includes raw fMRI data, as well as precomputed structural alignments for within-subject and group analysis. In addition to fMRI, simultaneously recorded cardiac and respiratory traces, as well the complete implementation of the stimulation paradigm, including stimuli, are provided. An initial quality control analysis reveals distinguishable patterns of response to individual genres throughout a large expanse of areas known to be involved in auditory and speech processing.
Subject species
homo sapiens
Modality
fMRI-BOLD
Cognitive paradigm (task)
auditory scene perception
Map type
Other
- n
studyforrest_rev003
- nitrc.org
Updated Nov 4, 2015ShareFacebookTwitterEmailClick to copy linkLink copiedCiteThe Study Forrest team, including centers in Germany and USA. See https://www.studyforrest.org. (2015). studyforrest_rev003 [Dataset]. https://www.nitrc.org/support/?group_id=833Dataset updatedNov 4, 2015AuthorsThe Study Forrest team, including centers in Germany and USA. See https://www.studyforrest.org.Dataset funded byMagdeburg UniversityDescriptionStudy Forrest. Extensive functional brain imaging data from natural stimulation, a rich set of auxiliary data (such as structural brain scans, measurements of physiological, and technical confounds), as well as stimulus annotations.
- N
A studyforrest extension, simultaneous fMRI and eye gaze recordings during...
- neurovault.org
niftiUpdated Jun 30, 2018+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCite(2018). A studyforrest extension, simultaneous fMRI and eye gaze recordings during prolonged natural stimulation: Emotions portrayed via visual cues (facial expressions, gestures) in a natural movie [Dataset]. http://identifiers.org/neurovault.image:14272niftiAvailable download formatsUnique identifierhttps://identifiers.org/neurovault.image:14272Dataset updatedJun 30, 2018LicenseCC0 1.0 Universal Public Domain Dedicationhttps://creativecommons.org/publicdomain/zero/1.0/
License information was derived automaticallyDescription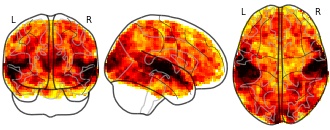
Collection description
Subject species
homo sapiens
Modality
fMRI-BOLD
Analysis level
group
Cognitive paradigm (task)
film viewing
Map type
Z
- Z
studyforrest-data-phase2: First public release
- data.niaid.nih.gov
- zenodo.org
Updated Jan 24, 2020+ more versionsShareFacebookTwitterEmailClick to copy linkLink copiedCiteHanke, Michael (2020). studyforrest-data-phase2: First public release [Dataset]. https://data.niaid.nih.gov/resources?id=zenodo_48421Dataset updatedJan 24, 2020Dataset provided byHoffmann, Michael
Adelhöfer, Nico
Kaule, Falko R.
Sengupta, Ayan
Hanke, Michael
Häusler, Christian
Baumgartner, Florian J.
Guntupalli, J. Swaroop
Stadler, JörgLicenseODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automaticallyDescriptionExtension of the dataset published in Hanke et al. (2014; doi:10.1038/sdata.2014.3) with additional acquisitions for 15 of the original 20 particpants. These additions include: retinotopic mapping, a localizer paradigm for higher visual areas (FFA, EBA, PPA), and another 2h movie recording with 3T full-brain BOLD fMRI with simultaneous 1000 Hz eyetracking.
Only open-source software was employed in this study. We thank their respective authors for making it publicly available.
Please follow good scientific practice by citing the most appropriate publication(s) describing the aspects of this datasets that were used in a study.
- g
Processing of visual and non-visual naturalistic spatial information in the...
- doi.gin.g-node.org
Updated Dec 15, 2021ShareFacebookTwitterEmailClick to copy linkLink copiedCiteChristian O. Häusler; Simon B. Eickhoff; Michael Hanke (2021). Processing of visual and non-visual naturalistic spatial information in the "parahippocampal place area": from raw data to results [Dataset]. http://doi.org/10.12751/g-node.7is9s6Unique identifierhttps://doi.org/10.12751/g-node.7is9s6Dataset updatedDec 15, 2021Dataset provided byPsychoinformatics Lab, Institute of Neuroscience and Medicine, Brain & Behaviour (INM-7), Research Centre Jülich, Jülich, Germany; Institute of Systems Neuroscience, Medical Faculty, Heinrich Heine University, Düsseldorf, GermanyAuthorsChristian O. Häusler; Simon B. Eickhoff; Michael HankeLicenseAttribution 4.0 (CC BY 4.0)https://creativecommons.org/licenses/by/4.0/
License information was derived automaticallyDataset funded byBMBF
NSFDescriptionThis repository contains the fMRI data, annotations, analysis scripts to generate the results, and results in Häusler C.O. & Hanke M. (submitted) as Datalad datasets (https://github.com/datalad).
- s
studyforrest_multires3t
- studyforrest.org
Updated Dec 18, 2020ShareFacebookTwitterEmailClick to copy linkLink copiedCiteAyan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael Hanke; Martin Kanowski; Claus Tempelmann (2020). studyforrest_multires3t [Dataset]. https://studyforrest.org/Dataset updatedDec 18, 2020AuthorsAyan Sengupta; Renat Yakupov; Oliver Speck; Stefan Pollmann; Michael Hanke; Martin Kanowski; Claus TempelmannLicenseODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automaticallyDescriptionExtension of a matching fMRI dataset (Sengupta, et al., 2017; OpenFMRI ds000113c) on participants performing a central fixation task while being stimulated with oriented visual gratings. This dataset extends the previous one with acquisitions for 3 matching spatial resolutions (1.4, 2.0, and 3.0 mm) at 3T (complementing the previous 7T acquisitions at 0.8, 1.4, 2.0, and 3.0 mm). Five of the total of seven participants are identical in both datasets. All participants are part of the studyforrest.org project.

Not seeing a result you expected?
Learn how you can add new datasets to our index.
FacebookTwitterstudyforrest_data_structural
ODC Public Domain Dedication and Licence (PDDL) v1.0http://www.opendatacommons.org/licenses/pddl/1.0/
License information was derived automatically
This dataset contains T1 and T2 weighted MRI scans, susceptibility weighted images, and diffusion imaging scans. These data are suitable for analyses of brain structure. For more information about the project visit: http://studyforrest.org